ChatSOP: An SOP-Guided MCTS Planning Framework for Controllable LLM Dialogue Agents
ChatSOP 把企业式标准操作流程引入 LLM 对话智能体,先离线预测 SOP 图,再在对话中用 SOP-guided MCTS 规划下一步动作。论文同时构建 SOP 标注多场景对话数据集,并展示该方法在动作准确率、主动性、可控性和任务完成方面优于 CoT 与 CoT+SOP 基线。
- 作者
- 机构
- College of Intelligence and Computing, Tianjin University, Tianjin, China天津大学智能与计算学部,中国天津
- Ping An Technology平安科技
- Tübingen AI Center, University of Tübingen图宾根大学图宾根 AI 中心
读前先抓住结论
ChatSOP 讨论的是一个很现实的矛盾:LLM 对话智能体越来越会聊天,却不一定会按业务流程办事。任务型对话里,用户不是来随便闲聊的,而是要完成信用卡激活、预约、售后、咨询、销售转化这类有明确步骤的目标。只要其中某个步骤被跳过,哪怕回复听起来很自然,任务也可能失败。
论文的核心判断是:可控对话不能只靠下一句回复生成,必须显式建模流程结构。为此,ChatSOP 把 Standard Operating Procedure,也就是 SOP,引入 LLM 对话智能体。SOP 在这里不是一句提示词,而是一个由智能体动作和用户状态组成的有向图;图上的边规定哪些状态和动作可以相连,哪些步骤必须先发生。
在这个基础上,ChatSOP 分成两个阶段。离线阶段,系统根据任务定义预测 SOP 图,得到一个邻接表;在线阶段,系统把当前对话状态放进 SOP-guided Monte Carlo Tree Search,也就是 SGM,用多步模拟选择下一轮智能体动作。LLM 仍然负责理解、判断和生成自然语言,但它不再单独决定流程,而是在 SOP 图和搜索算法的约束下工作。
论文还构建了 SOPDAIL 数据集。这个数据集的关键不只是有 3,114 段中文对话,而是每个任务都带有任务画像、用户画像、动作集合、用户状态、SOP 和对话路径等中间结构。这让研究者可以分别评测“能不能预测流程图”和“能不能沿流程生成对话”两个问题。
实验结果的主线很清楚:在 SOP 预测上,监督微调能显著提升图结构预测质量,Qwen1.5-72b 微调后 F1 达到 77.00,超过 GPT-4o 直接邻接表生成的 71.85;在对话生成上,SGM 在不同模型上普遍超过 CoT 和 CoT+SOP。例如基于 GPT-3.5 的智能体,SGM 的单轮动作准确率是 76.52,而 CoT 基线是 48.57,对应论文摘要中强调的 27.95% 绝对提升。
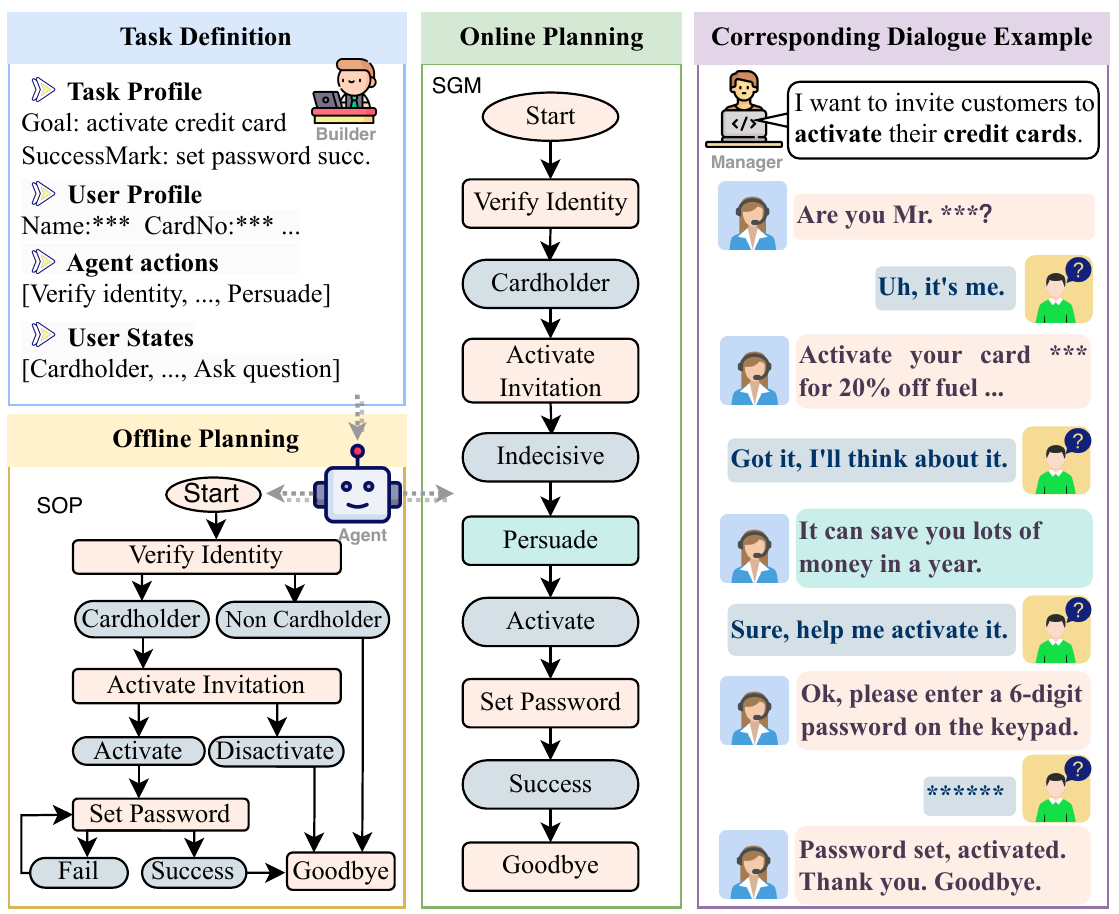
为什么任务型对话需要 SOP
任务型对话和开放域聊天的评价标准完全不同。开放域聊天里,回复有帮助、自然、有信息量通常就足够;任务型对话里,回复还必须符合流程。比如信用卡激活不能先介绍优惠再忘记身份核验,酒店入住不能绕开证件确认,售后处理不能在未确认问题类型前直接承诺解决方案。这些步骤不是语言风格问题,而是业务约束。
传统任务型对话系统通常依赖槽位、意图、规则树或人工设计的状态机。优点是流程可控,缺点是迁移成本高:换一个业务域,就要重新设计槽位和流程;遇到用户拒绝、追问、犹豫或偏离话题时,规则系统很难自然应对。LLM 刚好补上了理解和生成能力,却带来另一种风险:它可能给出看似体面的下一句,但从全局流程看已经跳步、漏步或提前结束。
论文在 Related Work 中把已有对话智能体分成几类:会话问答、开放域对话、任务型对话和会话推荐。前两类主要被动回应用户,任务型对话强调结构化服务,会话推荐强调主动引导目标。但现有对话规划常常还是贪心式的单轮预测,只关注下一步“像不像”,没有充分建模全局策略之间的依赖。ChatSOP 反过来问:如果我们先知道业务流程图,再选择动作,会不会更可控?
SOP 的价值就在这里。它不是替代 LLM,而是给 LLM 一个外部流程骨架。图中的节点可以是 Agent.VerifyIdentity、User.Cardholder、Agent.IntroduceActivationActivity 这类动作或状态;边表示允许的转移。这样,系统就能区分两类动作:一类是必须严格遵守流程的可控动作,另一类是回答问题、解释疑虑、尝试说服这类不一定写在 SOP 中、但对完成目标有帮助的主动动作。
只靠下一句生成
模型根据当前上下文直接生成动作和回复。局部可能流畅,但容易把流程约束藏在 prompt 里,遇到多步任务时会跳步、漏步或过早结束。
SOP + 搜索规划
系统先把流程转成图,再在当前对话状态下模拟未来动作路径。SOP 提供边界,MCTS 提供多步前瞻,LLM 提供判断和自然语言表达。
这里的关键不是把 SOP 简单塞进上下文。论文的实验恰好说明,CoT+SOP 已经比 CoT 更好,但仍然不如 SGM。原因是“知道流程”不等于“会规划流程”:模型可能在 prompt 里看到了 SOP,却仍然按单轮直觉选择动作。MCTS 的加入让系统能多步向前看,评估某个动作是否会在后续更容易达到目标。
数据集不是普通对话语料
ChatSOP 的数据集 SOPDAIL 值得单独理解,因为它决定了这篇论文不是只提出一个搜索算法,而是把可控对话拆成了可监督、可评测的结构化任务。SOPDAIL 覆盖 32 个领域、53 个任务和 3,114 段中文对话;更重要的是,它包含任务定义、用户画像、智能体动作、用户状态、SOP 邻接表、对话路径和完整脚本。
论文的数据构建流程是四步。第一步定义任务,包括业务内容、任务目标、成功标志、用户画像、动作集合和状态集合。第二步让 LLM 作为 planner 草拟 SOP,得到流程中的必要节点和连接。第三步让 LLM 作为 screenwriter,从 SOP 中采样多轮对话路径,并插入主动动作与用户反应。第四步让 LLM 作为 scriptwriter,把动作和状态路径改写成自然语言对话。每一步之后,人工标注者都会审查、修订和验证结果。
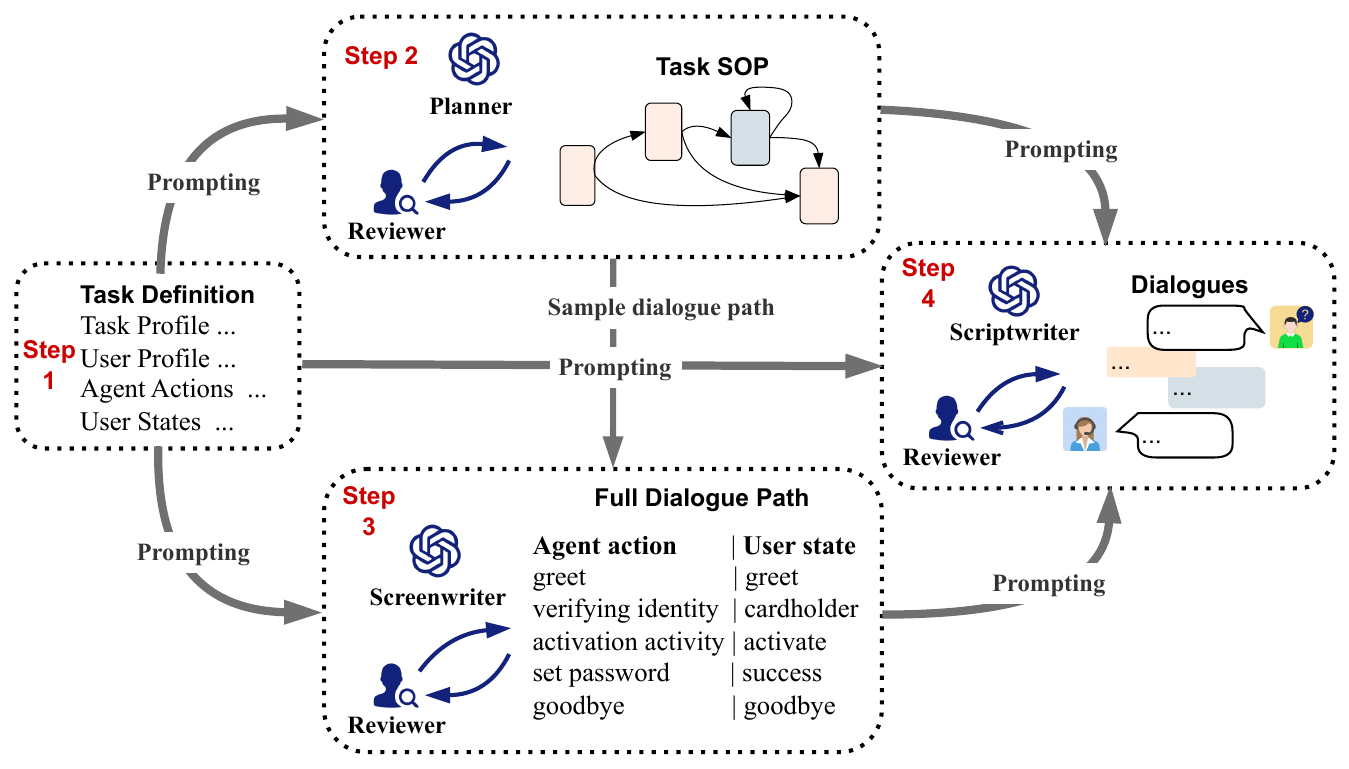
明确业务目标、用户画像、动作集合和状态集合
把必要业务流程转成 SOP 图或邻接表
从 SOP 中采样路径,并插入主动动作与用户状态
把结构化路径写成真实对话文本
检查流程、常识、知识和语言质量
这个流程的一个细节很重要:作者并没有完全相信 LLM 自动生成的数据。附录里写到,标注者需要先阅读指南、通过预标注,再进行正式标注;每个样本会分配给三名标注者交叉验证;平均每个样本标注 10.3 分钟,报酬为每小时 8 美元。换句话说,SOPDAIL 是“LLM 预生成 + 人工质检”的混合数据集,而不是纯合成数据。
数据集比较表说明 SOPDAIL 的定位。DSTC、CrossWOZ、SGD 等传统数据集更偏任务型服务,但不一定包含主动交互;OTTers 和 TOPDIAL 有主动性,却不强调流程可控。SOPDAIL 同时标注主动性和可控性,并覆盖开放定义的多领域业务任务。对 ChatSOP 来说,这类数据尤其关键,因为模型既要学会生成回复,也要学会流程图和动作路径。
更细地看,SOPDAIL 把“对话质量”拆成了几层。第一层是业务任务是否说清楚,例如服务方是谁、目标是什么、成功标志是什么、有哪些背景知识。第二层是用户信息是否足够,例如姓名、身份、账户或偏好等能否支撑身份核验和个性化服务。第三层是动作和状态是否覆盖业务过程,例如智能体能不能核验身份、介绍活动、答疑、尝试说服、礼貌结束,用户是否可能同意、拒绝、犹豫、询问或退出。第四层才是自然语言脚本是否流畅。这样的拆分让数据集不仅能训练回复生成,也能训练规划和评测。
这一点和很多对话数据集不同。普通对话语料往往只记录“用户说了什么、系统说了什么”,最多附带意图或槽位;SOPDAIL 则额外保存“这一轮为什么应该这样说”。如果模型选错了动作,研究者可以回到 SOP 图检查:是用户状态识别错了,还是候选动作不在可达邻接节点里,或者是主动动作虽然合理但未能推动任务目标。这样的可诊断性,是可控 agent 数据非常重要的价值。
论文中的 74% 可控性话语也值得注意。这说明数据集并不是以闲聊和补充说明为主,而是大量围绕流程节点展开。对模型来说,这会形成一种训练压力:它必须学会尊重业务顺序,而不是只学会生成自然、礼貌、信息充分的句子。对企业场景来说,这正好对应真实需求,因为业务系统最怕的不是回复不够漂亮,而是回复看起来漂亮但没有按流程完成关键步骤。
附录里的任务定义字段也很有工程参考价值。任务画像提供业务目标和知识,用户画像提供身份核验和个性化服务所需信息,智能体动作给出系统可选动作集合,用户状态给出用户当前任务状态。这样的结构让后续模型不必从一大段自由文本里猜测流程,而是可以在固定字段之间传递状态。
1{2 "task_profile": {3 "agent_identity": "Bank Credit Card Center Customer Service",4 "task_goal": "persuade the user to explicitly agree to activate the credit card",5 "success_mark": ["User.ClearAgreement"]6 },7 "agent_action": ["Agent.Start", "Agent.VerifyIdentity", "Agent.IntroduceActivationActivity"],8 "user_state": ["User.Cardholder", "User.WorryAndDoubt", "User.ClearAgreement"]9}这段结构化输入背后的思想是:把业务流程拆成可枚举、可连接、可检查的单元。对于想复用 ChatSOP 的工程团队,这可能比 MCTS 本身还先要做。没有清晰的动作集合、状态集合和成功标志,搜索算法很难知道什么叫“走对了流程”。
方法总览
ChatSOP 方法整体可以看成一条双阶段流水线:离线规划器先从任务定义中预测 SOP,在线规划器再把 SOP 当成约束,用 MCTS 规划下一轮动作。两者之间通过邻接表连接,邻接表就是业务流程图的机器可读表示。
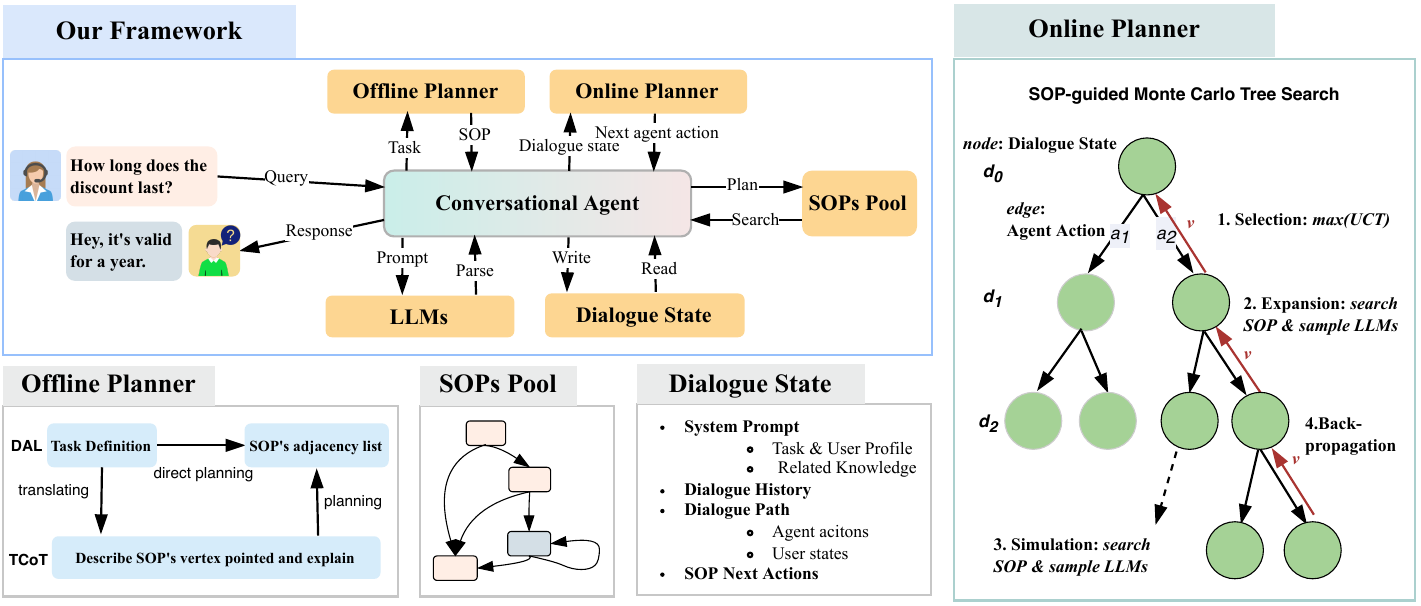
论文把 ChatSOP 拆成五个组件。LLM 模块负责管理和调用不同模型;SOPs Pool 存储可检索的 SOP 节点;Offline Planner 负责从任务定义中生成 SOP 邻接表;Online Planner 根据对话上下文规划下一步动作;Working Memory 维护历史对话、当前状态、任务信息和中间结果。这个结构让系统里的每个部件都有明确职责,而不是把所有判断都压进一个长 prompt。
工作流程从用户给出任务定义开始。系统先检索相关 SOP 节点,再由离线规划器生成完整邻接表。对话开始后,每轮用户输入都会更新工作记忆;在线规划器将当前状态作为搜索根节点,结合 SOP 图扩展候选动作,模拟未来对话路径,并把奖励回传到树中。最后,系统选择当前节点下价值最高的子节点,作为下一轮智能体动作,再让 LLM 生成自然语言回复。
从 SOPs Pool 中找到任务相关动作和状态
离线规划器生成邻接表,表示哪些节点可以相连
工作记忆根据历史对话和用户新话语维护当前状态
SGM 用选择、扩展、模拟和回传评估候选动作
LLM 根据选中动作生成自然语言回复
这套方法的设计重点是把流程控制分层。离线规划器解决“流程应该是什么”;在线规划器解决“当前上下文里下一步应该走哪条边”;LLM 回复生成解决“动作如何说成自然语言”。这样分层之后,系统的错误也更容易诊断:是 SOP 图错了,是状态识别错了,是搜索奖励错了,还是回复生成偏离动作了。
SOP 图如何变成控制信号
形式化目标
论文把一次多轮对话写成 。其中 是用户话语, 是用户状态, 是智能体动作, 是智能体回复。这个四元组很朴素,但它把对话从纯文本序列改成了“状态-动作-回复”的结构,后续才能做状态预测和动作规划。
SOP 图 是有向图,顶点标注为智能体动作和用户状态,边表示流程允许的连接。邻接表 则是图的实现形式:每个节点对应一个后继节点列表。SOP 预测任务就是判断这些连接是否存在。
在所有候选邻接关系中,选择在给定用户状态和智能体动作条件下概率最大的连接。它回答的是:当前动作或状态之后,SOP 图允许走向哪里。
这个公式看起来像普通分类问题,但它的意义更像流程编译。系统不是直接问“下一句话怎么说”,而是先问“流程图中哪些边应该存在”。如果 SOP 图被删边、加错边或漏掉关键节点,后面的在线规划就会基于错误流程做决策。因此论文强调,对 SOP 图的修改或删除会导致任务完成不准确。
随后,对话生成分成三步:先预测下一轮用户状态,再预测下一轮智能体动作,最后生成回复。三个条件概率都依赖历史对话、任务画像和 SOP 邻接表。直觉上,这等于把“先理解用户当前处于什么状态,再选择流程上合适动作,再说出回复”变成了明确建模目标。
离线规划器
Offline Planner 提供三种 SOP 预测方式。DAL 是最直接的:提示 LLM 直接输出 JSON 邻接表。它实现简单,但容易漏边或混淆节点关系。TCoT 多加一步,让 LLM 先用自然语言解释每个顶点和子顶点关系,再把解释转换成邻接表;这样做的动机是让模型先把业务流程讲清楚,再输出结构。SFT 则使用 SOPDAIL 的监督数据微调模型,让模型逐个顶点生成相邻节点。
直接提示模型生成邻接表,成本低但稳定性有限。
附录提示词揭示了这一步的工程形态。DAL prompt 要求模型扮演业务流程经理,根据任务画像和 SOP 顶点输出每个节点的邻接列表;TCoT prompt 先要求模型分析所有节点的交互过程,再把描述转成 JSON。这里的输出格式限制非常严格:字段必须包含所有节点,没有后继节点就返回空数组,节点名称必须与候选列表一致。这些限制能降低自由生成导致的结构漂移。
1{2 "Agent.Start": ["Agent.VerifyIdentity"],3 "Agent.VerifyIdentity": ["User.Cardholder", "User.NonCardholder"],4 "User.ClearRejection": ["Agent.PoliteEnd"],5 "Agent.PoliteEnd": []6}这段邻接表示例说明了 SOP 图的核心:流程中每个节点都知道自己可以走向哪里。在线规划器看到当前状态是 User.Cardholder 时,不必从所有动作里盲选,而是可以优先考虑 SOP 局部子图中的动作。这也是 ChatSOP 区分“控制”和“生成”的关键。
从实现角度看,离线规划器的难点不是把 JSON 格式写对,而是把业务流程边界判断对。比如“核验身份之后可以进入介绍活动”是业务主干边;“用户提出疑问之后可以答疑”可能是主动交互边;“用户不是本人之后继续介绍活动”则应当被禁止。DAL 容易在这类边界上犯错,因为它直接从任务画像跳到邻接表;TCoT 先让模型解释节点关系,能让部分隐含约束被显式说出来;SFT 则让模型从人工修订过的数据中学习这些边界。
这也解释了为什么论文会同时保留三种离线方法。DAL 是低成本起点,适合快速生成候选 SOP;TCoT 是无训练条件下的推理增强,适合让模型先把流程讲清楚再结构化;SFT 是有数据积累后的稳定方案,适合把反复出现的业务流程知识沉淀进模型参数。实际系统可以把三者串起来:先用 DAL 或 TCoT 生成草稿,再由人修订,积累到一定规模后再做 SFT。
SOP 邻接表还有一个工程上的好处:它可以被版本化和审计。业务规则变化时,不必重新写整套对话 prompt,而是更新局部边或节点;线上出现事故时,也可以回放当时系统走过的节点序列,判断是否违反 SOP。如果对话智能体只是一个长 prompt 和一段历史上下文,这种审计会困难得多。
在线规划器:SOP-guided MCTS
在线阶段的目标是选择下一轮实际对话动作。论文把每个搜索节点看作对话状态 ,其中包含智能体动作和用户状态。搜索从初始状态 开始,经过选择、扩展、模拟和回传四个阶段。经过若干次迭代后,系统从当前节点的子节点中选择 值最高的动作,用于下一轮真实对话。
SGM 的核心不是“让模型想得更久”这么简单,而是把每一次思考都放进可更新的搜索树里。普通 CoT 通常只产出一条思考路径,路径中前面一步错了,后面很难恢复;ToT 虽然有多条候选思路,但如果没有清晰的回传机制,历史尝试对下一轮选择的影响仍然有限。MCTS 的优势是每次模拟都会改变访问计数和价值估计,让系统逐渐偏向更有希望的动作分支。
在对话场景里,这种价值累积尤其重要。一个动作当前看起来合理,不代表几轮后仍然能完成任务。例如用户刚完成身份核验时,直接结束对话显然不合理;介绍活动可能推动目标,但如果用户表示担心风险,就需要先答疑而不是继续硬推。MCTS 通过模拟后续状态,让系统把“当前动作对未来路径的影响”也纳入选择。
UCT 与奖励
选择阶段使用 UCT 来平衡探索和利用。高价值节点值得利用,访问次数少的节点值得探索。公式如下:
第一项 表示在状态 采取动作 的期望价值;第二项是探索项,访问少的子节点会得到更大探索奖励; 控制探索和利用的平衡。
这里的 值不是简单的文本相似度,而是由逻辑合理性和任务完成程度组成。论文用 LLM prompt 多次评估当前动作是否合理,得到 ;同时用离散值表示任务完成状态,终止状态为 0.3,成功状态为 0.7,其他为 0。
衡量动作逻辑合理性, 衡量任务完成状态, 是权重。论文实验中 ,因此主要依赖 LLM 对动作合理性的二值采样评估。
这个奖励设计有一个值得注意的边界:当 时,任务完成函数 实际被弱化了。论文这样设可能是为了让 LLM 逻辑判断主导搜索,但工程复用时可以重新调权重。如果业务目标非常明确,例如是否完成激活、是否预约成功,增加任务完成奖励可能更稳。
奖励函数还有一个隐含假设:LLM 能较可靠地判断动作是否符合流程或有助于任务成功。这个假设在强模型上通常成立,但在小模型或高风险业务上未必足够。因此复用时可以把奖励拆成多个来源,例如 SOP 图硬约束、规则校验、知识库校验、用户情绪或合规检测,再把 LLM 判断作为其中一项。这样能减少单一模型裁判造成的偏差。
原文算法拆解
1Require: Initial dialogue state , transition function , reward function , action generator 2Require: expand actions , depth limit , roll-outs , exploration weight 3Initialize action memory , children , rewards , value function , visit counter 4for :5 6 while : # Selection7 update visit count 8 choose by UCT over actions in 9 move to child state 10 while is not terminal and : # Expansion and Simulation11 for :12 sample action , next state , reward 13 update action memory, child mapping, and rewards14 choose action with maximum local reward for simulation15 move to next state and continue16 for : # Back propagation17 update with future rewards这段算法把 ChatSOP 的在线规划压缩成初始化、选择、扩展、模拟和回传。SOP 影响候选动作扩展,LLM 提供动作生成、状态转移和奖励判断,MCTS 负责把多次模拟结果沉淀到 值中。
算法输入分三类。第一类是对话状态与模型接口:初始状态 、状态转移函数 、奖励函数 、动作生成器 。这些接口通常由 LLM prompt 实现。第二类是搜索预算:扩展动作数 、深度限制 、roll-out 次数 。第三类是探索权重 ,决定 UCT 中探索项的强度。
初始化阶段建立动作记忆 、子节点映射 、奖励表 、价值函数 和访问计数 。这些数据结构让每次模拟不只是一次独立调用,而是会改变搜索树的经验。访问次数告诉算法哪些路径已经看过,奖励和 Q 值告诉算法哪些路径更有希望。
选择阶段只在已有树中移动。从根状态开始,只要当前状态已经访问过,算法就用 UCT 从已有动作中选一个。这个阶段不会创造新动作,主要是在已经积累经验的分支里找到值得继续探索的叶节点。对于对话任务来说,它相当于沿着当前认为有希望的动作路径向前走。
扩展阶段发生在非终止叶节点。系统采样 个候选动作,并通过状态转移函数预测后继状态,通过奖励函数估计奖励。论文在这里加入 SOP 约束:先利用 SOP 图的局部子图,再加入当前状态后两级子节点进行扩展。这样既不会完全锁死在 SOP 上,也不会让 LLM 任意跳到无关动作。
模拟阶段用于估计未来收益。为了效率,论文没有让搜索在全部空间中高随机性展开,而是沿着 LLM 采样并受 SOP 引导的候选对话策略向下模拟。这是一个很务实的取舍:任务型对话需要实时性,模拟过深过宽会让延迟和成本不可接受。
回传阶段把终止路径上的未来奖励聚合到各个状态动作对的 值中。完成预定迭代后,系统从当前节点的子节点中选 值最高的动作,指导真实对话的下一轮。这一步体现了 MCTS 与普通 CoT 的差异:CoT 只生成一条推理链,MCTS 会把多条候选路径的经验累积起来。
把这套算法落到真实系统时,还需要明确每个函数如何实现。动作生成器可以是一个提示词,让模型从候选动作列表中采样若干动作;状态转移函数可以让模型根据动作和上下文预测用户可能状态;奖励函数可以让模型判断动作是否符合 SOP 或推动目标。论文附录给出的提示词正是在定义这些接口。也就是说,SGM 并没有要求训练一个传统强化学习环境,而是用 LLM 模拟策略、世界模型和奖励模型。
不过,LLM 同时扮演多个角色也会带来相关性风险。如果动作生成、状态转移和奖励判断都由同一个模型完成,模型可能把自己的偏好重复强化。工程上可以用不同模型、规则检查或人工反馈来分离这些角色。例如用小模型生成候选动作,用规则和 SOP 图过滤,用强模型评分,用真实用户反馈或日志更新奖励。这些都能让 MCTS 更接近可部署系统。
还要注意,SOP-guided MCTS 并不是越深越好。深度越大,模拟更可能覆盖未来情况,但也更容易把模型生成的虚假用户反应带入决策。宽度越大,候选动作更多,但成本更高。论文使用 、、 是一种折中:足够进行多步规划,但不至于让搜索完全不可控。复用时应把这些参数视为产品延迟和业务风险之间的旋钮。
实验结果怎么读
实验分成两条线:SOP 预测和对话生成。SOP 预测回答“能不能从任务定义恢复流程图”;对话生成回答“有了流程图之后,能不能沿流程选择动作并生成对话”。这两个任务分别对应 ChatSOP 的离线规划器和在线规划器。
SOP 预测指标包括 Pre、Rec、F1、GED 和 GEDR。Precision 和 Recall 衡量预测边是否正确、是否漏掉真实边,F1 是二者折中;GED 是图编辑距离,GEDR 是编辑比例,二者越低说明预测图越接近真实 SOP。读这张表时不要只看 F1,还要看 GED/GEDR,因为一个看似高 F1 的图如果需要大量编辑才能匹配真实流程,部署风险仍然高。
主结果显示,TCoT 在多数模型上优于 DAL,特别是召回和 F1 有提升,说明“先解释关系再转邻接表”确实能改善部分模型的流程可用性。但提升最大的还是 SFT。Qwen1.5-72b 经过监督微调后 F1 达到 77.00,GEDR 降到 7.12;Llama3-8b SFT 也能达到 70.21 的 F1,明显超过它的 DAL 和 TCoT。这个结果说明 SOPDAIL 的结构化标注确实能训练模型掌握 SOP 预测。
对话生成指标包括 Acc T、Acc C、Acc P 和 Acc D。Acc T 是单轮动作准确率,Acc C 是可控动作准确率,Acc P 是主动动作准确率,Acc D 是整段对话准确率。整段对话准确率通常更难,因为它要求每一轮都正确;一个中间动作错了,后续即使语言流畅也可能不能算成功。
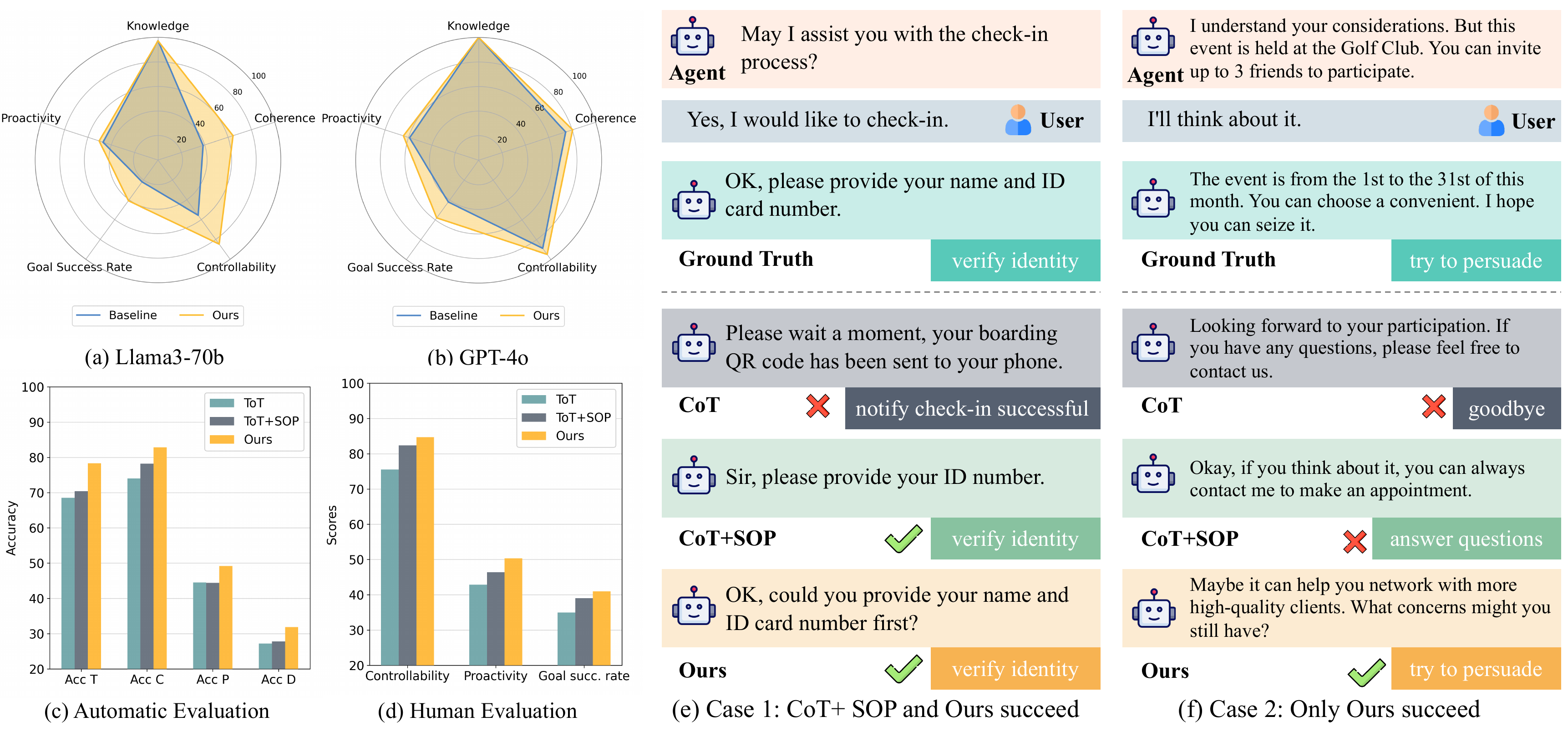
对话生成表的趋势很一致:SGM 基本在所有模型和指标上优于 CoT 与 CoT+SOP。以 GPT-3.5 为例,CoT 的 Acc T 是 48.57,CoT+SOP 提升到 63.24,SGM 进一步提升到 76.52。这说明把 SOP 放进 prompt 有帮助,但多步搜索规划还能带来额外收益。GPT-4o 上同样如此,SGM 的 Acc C 达到 91.19,说明强模型也会从 SOP-guided search 中获益。
开源模型结果也有一个清晰信号:模型规模仍然重要。Llama3-70b 的 SGM Acc T 是 78.35,而 Llama3-8b 是 46.85,差距很大。这说明 SOP 和 MCTS 不是万能补丁,底层模型仍需要足够的理解、状态识别和动作判断能力。另一方面,Qwen1.5-72b、Llama3-70b 这类开源模型在加入 SGM 后能接近甚至在某些维度超过较弱闭源基线,说明结构化流程和搜索能放大小模型可用性。
整段对话准确率 Acc D 普遍比单轮动作准确率低很多,这也符合任务型对话的连乘效应。单轮动作 80% 正确看起来不错,但一段对话有多轮时,任何一轮错都可能影响任务完成。SGM 的价值不是只把某一轮选择做对,而是降低整条路径中发生流程错误的概率。这也是为什么论文还要看目标成功率和人工评测。
SOP 预测结果
SFT 通常最强,说明结构化 SOP 标注能显著提升流程图预测。Qwen1.5-72b SFT 的 F1 为 77.00,超过 GPT-4o DAL 的 71.85。
对话生成结果
SGM 通常最强,说明仅有 SOP prompt 不够,多步模拟和回传能进一步提高动作准确率、可控性和整段任务完成。
人工评测补上了自动指标的盲区。作者在 100 段对话上评估可控动作、主动动作、知识准确率、目标成功率和逻辑连贯性。Llama3-70b 上,SGM 在可控性、目标成功率和连贯性上都有明显优势;GPT-4o 基线已经很强,但 SGM 仍能提升多个维度。知识准确率在各方法上都较高,说明主要瓶颈不是模型不知道业务知识,而是能不能按流程选择合适动作。
这个结论很关键。许多企业对话系统的问题不是“模型不知道答案”,而是“模型在错误时间说了正确答案”。例如用户还没有确认身份时,模型可能已经开始介绍优惠;用户表达担忧时,模型可能直接结束对话;用户已经同意时,模型可能继续说服。这些错误用知识准确率看不出来,但会体现在可控动作准确率、主动动作准确率、目标成功率和逻辑连贯性里。
因此读实验时应把指标和机制对应起来。SOP 预测表主要验证 Offline Planner 和 SOPDAIL 标注是否有用;对话生成表主要验证 Online Planner 是否能把 SOP 约束转化为更好的动作;人工评测验证自然语言回复是否在实际对话维度仍然可靠;成本效果分析说明这种可靠性需要付出多少计算代价。四类证据合在一起,才支撑论文的核心主张。
消融、成本与案例
论文还比较了 Tree-of-Thought 和 MCTS。ToT 也属于树式思考,但更偏把推理拆成多次 LLM 调用;MCTS 则有明确的选择、扩展、模拟和回传机制。结果显示,SOP 加入 ToT 也能提升性能,说明 SOP 本身是有效控制信号;但 SGM 在自动评测和人工评测中更好,说明 MCTS 的回传和价值累积更适合在线动作规划。
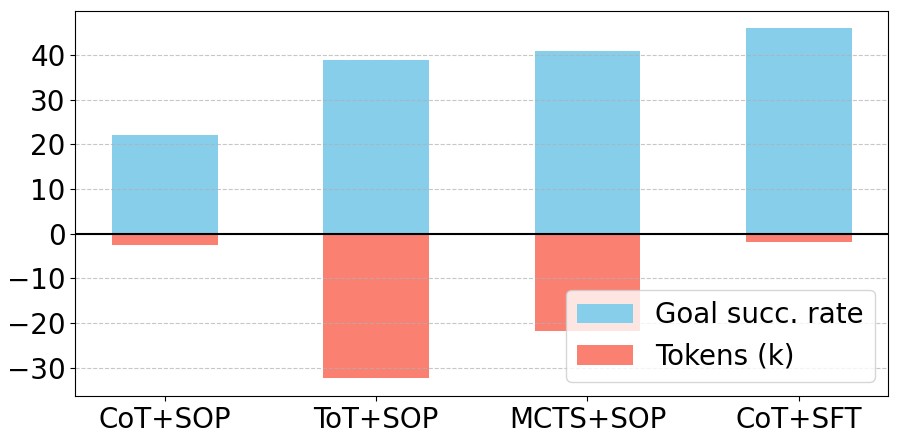
成本分析给了一个非常工程化的提醒:树搜索不是免费的。附录中,作者用 Llama3-70b-chat 比较目标成功率和 token 消耗。相对基础单步 CoT,MCTS 消耗约 9 倍 token,但目标成功率提升约 30%;相比 ToT,MCTS 更省 token 且效果更好;SFT 则在性能和计算效率上最好。
这意味着 ChatSOP 的部署形态不一定只有一种。如果系统已经积累了大量 SOP 标注数据,SFT 可能是更高效的长期方案;如果新任务很多、标注不足,SGM 可以作为少样本或零样本阶段的规划器;如果场景实时性要求极高,则需要限制搜索深度、roll-out 次数和候选动作数。
案例研究最能说明 MCTS 的优势。第一个案例中,办理某项业务前必须先核验身份;加入 SOP 后,CoT+SOP 和 SGM 都能选择符合流程的动作。第二个案例更有意思:最佳动作不在 SOP 中,而是主动说服。CoT+SOP 因为过度依赖显式 SOP,没有继续说服;SGM 通过模拟更深的对话路径,选择了更有利于目标达成的动作。这说明 SOP 不是把系统变成死规则,而是给主动规划提供边界。
附录中的提示词也证明了这一点。动作采样 prompt 会给出候选动作、对话上下文和 SOP 优先动作;奖励 prompt 会判断所选动作是否符合任务流程或有利于推动任务成功;用户状态 prompt 会根据当前对话选择最匹配状态。也就是说,MCTS 的每个接口都由 LLM 执行,但接口输入输出被严格结构化。
如果把案例放进更长的产品流程里看,ChatSOP 更像一个“决策层”而不是“话术层”。话术层决定一句话怎么表达,决策层决定现在是否该核验身份、是否该答疑、是否该继续说服、是否该结束。许多 LLM 应用失败,是因为把这两个层次混在一起,让一个生成模型同时负责状态识别、流程判断、目标优化和语言表达。ChatSOP 的贡献之一,就是把这些职责拆开。
成本章节也提示了一个部署策略:可以把 MCTS 用在困难轮次,而不是每一轮都跑完整搜索。比如问候、确认收到、简单解释可以用浅策略;身份核验、用户拒绝、关键成交、投诉升级等高风险节点再启用 SGM。这样可以保留多步规划带来的可控性,同时降低平均延迟和 token 成本。
另一个可行策略是把搜索结果缓存或蒸馏。大量相似任务反复出现时,可以把 MCTS 产生的高质量轨迹加入训练数据,后续用 SFT 模型直接预测动作。论文成本图里 SFT 的性能和效率最好,正好说明这种路径有价值:先用搜索探索策略,再用监督学习把策略固化下来。
局限与复用启发
ChatSOP 的第一类风险是 SOP 质量。如果离线预测出的 SOP 图有错,在线 MCTS 会在错误图上规划。搜索算法能缓解局部贪心,但不能凭空修复错误业务流程。因此真实系统里,关键任务的 SOP 仍然需要人工审核、版本管理和异常监控。
第二类风险是 LLM 幻觉。论文在局限中指出,方法依赖 ChatGPT、GPT-4 等模型的上下文学习能力,而 LLM 可能产生超出事实或业务规范的信息。SOP 可以约束动作路径,但不能保证自然语言回复中的每个业务细节都准确。涉及金融、医疗、法律等高风险场景时,知识库校验、工具查询和人工兜底仍然必要。
第三类风险是运行成本。MCTS 的宽度、深度和 roll-out 次数越大,越可能找到好策略,但响应延迟和 token 成本也越高。论文实验中 、、、,这是一个可控预算;实际部署时可以根据任务重要性动态调整,例如普通咨询用浅搜索,高价值交易或投诉处理用更深搜索。
伦理上,论文强调方法不应强迫智能体达成指定目标,也不应强迫用户接受业务结果。这个提醒很必要,因为“可控”和“说服”在业务对话中容易越界。SOP 应该用于保证流程合规、信息准确和用户体验,而不是用来操纵用户。面向真实业务时,需要明确告知、隐私保护、拒绝权和人工申诉通道。
对工程复用来说,可以先不完整复刻 ChatSOP,而是按三个层级迁移。第一层,把任务画像、用户画像、动作集合、用户状态和成功标志结构化;第二层,把 SOP 表示成邻接表,并记录每次对话走过的状态动作路径;第三层,再引入搜索或微调,用真实评测反馈优化动作选择。只要前两层做好,后续无论接 MCTS、规则系统还是监督模型,都有了可审计的中间结构。
最后,ChatSOP 给 agent 研究的启发是:很多“LLM 不可控”的问题,不一定只能靠更强模型解决,也可以靠更清晰的外部结构 + 搜索反馈解决。SOP 图负责表达人类业务先验,MCTS 负责把先验用于多步规划,LLM 负责语言理解和生成。三者分工清楚时,对话智能体才更接近可部署的业务系统。
如果要在自己的 agent 项目中复用这篇论文,可以从一个小任务开始。先列出成功条件,例如“用户明确同意激活”“预约时间和地点确认完成”“售后工单创建成功”。再列出必要动作和可能用户状态,把它们连成最小 SOP 图。然后收集几十段真实或模拟对话,用人工检查每轮动作是否符合 SOP。最后再决定是否需要 MCTS。如果简单规则已经足够,就不必引入搜索;如果用户反应复杂、流程分支多、主动动作影响成功率,再加入 SGM。
复用时还应保留失败日志。每当系统选择动作失败,应记录当前任务画像、用户画像、历史对话、预测用户状态、候选动作、SOP 可达节点、搜索奖励和最终回复。这样的日志能帮助团队判断失败来自哪里:是状态识别错、SOP 缺边、奖励函数偏差,还是回复生成没有忠实执行动作。ChatSOP 的结构化设计天然适合这种诊断。
在评测体系上,也不要只看最终成交率或用户满意度。ChatSOP 的指标拆分给了一个更细的诊断模板:先看每轮动作是否正确,再看可控动作是否符合 SOP,再看主动动作是否真的推动目标,然后看整段对话是否成功。这样做可以避免一个常见误判:系统最终成功了,但中间其实多次违反流程;或者系统没有成功,但每一步都合规,只是用户真实意愿不接受。前者需要修可控性,后者不应被简单判为模型失败。
主动性尤其需要单独评估。任务型对话如果只追求 SOP 合规,很容易变成僵硬的流程机器人;如果只追求主动推进,又可能变成过度说服。论文把主动动作和可控动作分开,是因为二者对应不同风险。可控动作的错误通常是流程违规,主动动作的错误通常是目标过度、上下文不合适或用户体验下降。实际系统中可以为主动动作设置更严格的触发条件,例如用户表达疑问时答疑,用户犹豫时解释利益和风险,用户明确拒绝时礼貌结束,而不是无限尝试说服。
SOP 图的粒度也需要设计。节点太粗,比如只有“介绍业务”和“结束”,无法约束关键步骤;节点太细,比如把每一句话都变成节点,会让图复杂到难以维护。论文的做法是把节点定义为业务动作和用户状态,而不是自然语言话术。这个粒度比较适合复用:动作足够抽象,可以让 LLM 灵活表达;状态又足够具体,可以支撑流程判断。
还有一个容易忽略的边界是跨任务泛化。论文通过按任务级别划分训练、验证和测试来避免任务重叠,这比按对话随机划分更严格。原因是如果同一任务的不同对话同时出现在训练和测试中,模型可能只是在记住某个业务流程,而不是真正学会从任务定义预测 SOP。实际业务评估也应采用类似方式:用新业务、新流程或新产品测试模型,而不是只用同一流程的换皮对话。
对安全和合规场景,ChatSOP 还可以和权限系统结合。某些动作可以被标记为高风险动作,例如收集敏感信息、承诺费用、确认交易、修改账户状态。MCTS 可以提出这些动作,但执行前必须通过规则或人工审批。这样,搜索算法提供候选,合规系统决定是否允许执行,LLM 负责把获批动作表达给用户。这个分层能减少 agent 自主性带来的风险。
从产品体验看,SOP 也不应暴露成生硬流程。用户不关心系统内部节点叫 Agent.VerifyIdentity,只关心对话是否自然、是否尊重自己、是否解决问题。因此最终回复生成仍然很重要。ChatSOP 的动作规划只决定“现在该做什么”,不决定“必须怎么说”。好的实现应当在动作层严格,在话术层灵活:同一个核验身份动作,可以根据用户语气、历史关系和业务场景生成不同表达。
还有一个实践细节是状态更新频率。ChatSOP 每轮都要根据用户话语更新用户状态,再据此规划下一动作。如果用户一句话里同时包含多个信号,例如既确认身份又提出疑问,系统需要决定当前主状态是什么,或者允许一个复合状态进入搜索。论文的数据结构以单个用户状态为主,适合清晰流程;复杂业务中可以扩展为多标签状态,或者把主要状态和辅助意图分开记录。这样既能保持 SOP 主干稳定,也能处理用户临时提问。
多轮对话还会遇到状态回退。用户可能先同意,后面又反悔;可能先拒绝提供地址,经过解释后又愿意继续;也可能在中途切换到另一个任务。严格有向 SOP 图如果只允许向前走,就不一定能覆盖这些情况。工程实现可以在 SOP 中显式加入回退边、异常边和转人工边,也可以让 MCTS 在主动动作中选择澄清、确认和重设状态。这样系统既不破坏业务主流程,又能处理真实用户的非线性行为。
论文没有把响应内容评价作为主线指标,但真实部署中仍然要关注。一个动作选对了,回复也可能失败,比如语气过强、解释不清、遗漏必要免责声明、暴露隐私信息。比较稳妥的做法是把动作规划和回复审查分开:先由 SGM 选动作,再由回复生成模块写话术,最后用合规检查、知识检查和风格检查过滤。这样可以避免“动作正确但话术违规”的隐患。
如果任务非常长,完整 MCTS 也可能面临树膨胀。可以采用分段规划:先规划当前阶段目标,例如完成身份核验;阶段完成后再切到下一个局部目标,例如介绍活动或设置密码。每个阶段都有自己的局部 SOP 子图和终止条件。这样的层级化搜索能降低分支数量,也更符合企业流程中“阶段门”的管理方式。
ChatSOP 的另一个启发是把评测数据设计成训练数据。人工评测中标出来的可控错误、主动错误、知识错误和连贯性错误,都可以反过来成为奖励模型或监督微调样本。比如某次对话中模型在用户明确拒绝后继续说服,这不仅是一个失败案例,也是一条负样本边界:在该用户状态下,某些动作应被降权或禁止。把这些失败案例系统化收集,能让可控对话从一次性论文实验变成持续优化过程。
对于多业务团队,SOP 图还可以成为产品、法务、运营和算法之间的共同语言。产品定义用户路径,法务确认哪些节点必须出现,运营维护话术和异常处理,算法负责状态识别和动作选择。相比一段难以审计的长提示词,图结构更容易开会讨论、版本对比和责任划分。
论文也提醒我们,LLM agent 的“自主性”不应被理解为完全自由决策。更可靠的自主性,是在明确目标、明确边界、明确反馈的环境里做局部选择。ChatSOP 让 LLM 在 SOP 约束内选择动作,并通过搜索评估未来路径,这比让模型凭一句系统提示自行判断要稳得多。
如果把这篇论文放到更大的 agent 架构视角下,它其实是在给 planner 模块加外部制度。很多 agent 系统有工具、记忆和执行器,却缺少一套能表达业务规范的规划约束。SOP 图正好扮演这个角色:它不是知识库,也不是工具 API,而是告诉 agent 哪些动作顺序是允许的、哪些动作必须被避免。
因此,ChatSOP 最适合那些目标明确、流程可写、错误代价较高、但用户反应又有一定多样性的场景。如果任务完全开放,SOP 会过度约束;如果任务完全固定,传统状态机可能更便宜。它的优势区间,是规则系统太硬、纯 LLM 又太松的中间地带。
阅读这篇论文时,也可以把 SOP 看成一种“任务契约”。用户画像、任务画像、动作集合和状态集合定义了契约的边界,MCTS 在契约内寻找最优路径,人工评测检查契约是否被遵守。这个视角能帮助我们避免把可控性误解成单纯的提示词技巧。
它最终强调的是一种朴素但常被忽略的工程原则:越是让模型自主行动,越要把目标、边界、状态和反馈显式化。ChatSOP 的价值就在于把这些东西都放到了可观察的中间层。
这也是它对后续可控 agent 系统最直接、最值得落地验证和持续迭代改进优化的重要启发。
如果要继续推进这条研究线,一个自然方向是把 SOP 学习和在线反馈闭环打通。当前论文中,SOP 主要来自离线预测和人工标注;在线 MCTS 使用这个 SOP 做规划。未来可以把真实对话中的成功和失败反馈回 SOP 图,例如某条边经常导致失败,就降低其优先级或触发人工复核;某个主动动作在某类用户状态下效果好,就把它加入局部候选策略。这样,SOP 就不只是静态业务流程,而是可持续改进的流程知识库。
从研究角度看,ChatSOP 也留下了几个后续问题。第一,SOP 图能否自动从企业文档、客服手册或历史工单中抽取,而不是依赖人工定义动作和状态。第二,奖励函数能否引入真实用户反馈,而不是只依赖 LLM 判断。第三,搜索能否和长期记忆结合,让系统记住某类用户在某类业务中的常见反应。第四,如何在可控流程和用户自主之间保持平衡,避免“为了达成目标而过度说服”。这些问题都直接关系到 LLM agent 在真实业务中的可靠性。