AFlow: Automating Agentic Workflow Generation
AFlow 将 agentic workflow 优化建模为代码表示工作流空间中的搜索问题,并使用蒙特卡洛树搜索结合执行反馈自动发现高性能工作流。在六个基准上,AFlow 相比手工方法平均提升 5.7%,相比自动 workflow 优化方法提升 19.5%。
- 作者
- 机构
- DeepWisdom深度智慧
- The Hong Kong University of Science and Technology (Guangzhou)香港科技大学(广州)
- Renmin University of China中国人民大学
- Nanjing University南京大学
- Fudan University复旦大学
- King Abdullah University of Science and Technology阿卜杜拉国王科技大学
- Université de Montréal & Mila蒙特利尔大学与 Mila
- The Hong Kong University of Science and Technology香港科技大学
读前先抓住结论
AFlow 要解决的问题很朴素,却卡在很多 agent 工程的核心位置:复杂任务常常不是一次 LLM 调用就能完成,而是要靠一套由生成、检查、修复、投票、测试、格式化等步骤组成的 agentic workflow。过去这些 workflow 往往由人手工设计,例如给数学题加 CoT、给代码题加测试和修复、给问答题加答案格式化。AFlow 的出发点是:既然这些流程会显著影响结果,能不能让系统自己搜索出适合任务的 workflow?
论文的关键转向是把 workflow 当成 可执行代码结构,而不是一段自然语言策略。节点表示一次 LLM 调用或工具/算子调用,边表示代码里的执行顺序、条件分支、循环和数据流。这样一来,候选 workflow 可以被真实运行、得到验证集分数、产生日志和成本,再被搜索算法继续修改。AFlow 因此不是单纯的 prompt optimization,而是 workflow program optimization。
方法上,AFlow 使用一个 MCTS 变体。每个搜索树节点代表一整个 workflow,边代表一次修改。每轮搜索经历选择、扩展、评估和回传:先根据分数和探索概率选择一个父 workflow,再让 LLM 优化器基于经验生成新 workflow,然后在验证集上执行多次获得反馈,最后把性能、修改说明、成功或失败经验写回树结构。这个闭环让 LLM 不再只靠“看起来合理”的自评,而是不断被真实任务结果校正。
实验结果给出几个很强的信号。AFlow 在 HotpotQA、DROP、HumanEval、MBPP、GSM8K 和 MATH 六个基准上平均达到 80.3%,比手工设计方法平均高 5.7%,比 ADAS 这类自动 workflow 优化方法高 19.5%。成本分析还显示,AFlow 找到的 workflow 能让较弱或更便宜的模型进入更好的成本-性能前沿,例如在 HumanEval 上用 DeepSeek 执行 AFlow 搜索出的 workflow,可以以 GPT-4o IO 约 4.55% 的成本达到相近表现。
问题背景:为什么 workflow 不能再靠手写
LLM agent 做复杂任务时,真正起作用的往往不是某一句 prompt,而是一整套流程。代码生成可能需要先生成多个候选,再写测试,再运行,再修复;数学题可能需要先分解,再执行辅助计算,再格式化最终答案;问答任务可能需要检索、推理、压缩和答案规范化。论文把这些结构统称为 agentic workflow。它们本质上是“怎么组织多次模型调用和中间信息”的工程方案。
手写 workflow 的问题在于,它依赖经验,也依赖任务。一个在 HumanEval 上有效的“生成-测试-修复”流程,不一定适合 HotpotQA;一个对 GPT-4o-mini 有用的流程,也未必是 DeepSeek-V2.5 的最佳流程。随着任务增加,人需要为每类任务反复试错,人工成本很高,而且很难系统探索“是否应该加 ensemble、是否应该先 format、是否应该保留 review、是否应该引入代码执行”这类结构选择。
已有自动化方法各自解决了一部分问题。DSPy 等方法可以优化 prompt 或模块参数,但通常仍需要人先搭好初始 workflow。TextGrad、GPTSwarm、ADAS 等工作尝试让模型参与流程优化,但要么搜索空间受限,要么把历史 workflow 线性塞进提示词,导致 LLM 难以准确复用某条成功路径,也难以避开某个失败分支。AFlow 的论文定位正是在这里:既保留代码空间的表达能力,又用树搜索组织历史经验。
只优化 prompt
适合改写单个节点的输入,但很难改变流程结构,例如是否增加测试、投票、修复、条件分支或多轮反思。
优化 workflow
直接搜索节点、算子和代码边组成的可执行流程,让结构变化也能被评估、比较和复用。
从 agent 领域看,这个问题很重要。许多论文都会展示一个精心设计的流程图,但读者很难判断:这个流程是否只是作者经验?换数据集是否还有效?某个模块是否真的带来增益?AFlow 把这些问题转成可运行的搜索和消融:如果一个 workflow 修改有效,它应该在验证任务上体现为分数提升;如果无效,就应该作为失败经验写回搜索树。
从形式化到可执行 workflow
论文先定义 workflow 的基本元素。一个 agentic workflow 由一系列 LLM 调用节点组成,节点集合可以记为 。每个节点 都有若干参数:调用哪个模型 ,使用什么提示词 ,温度 如何设置,输出格式 是 JSON、Markdown、XML 还是 raw text。这些节点通过边 连接,边决定执行顺序和信息如何流动。
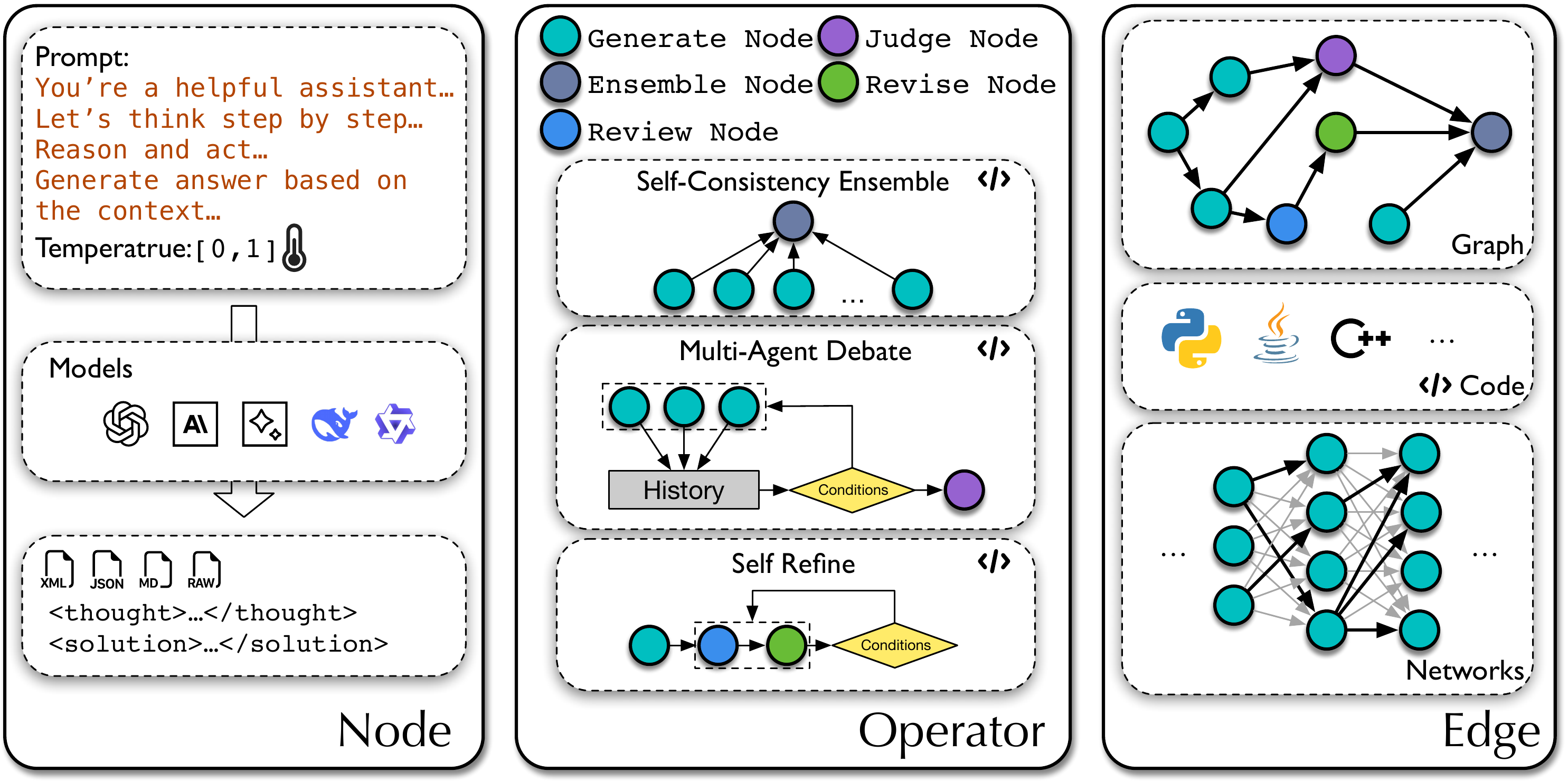
论文特别强调 代码表示的边。如果边只是普通图结构,那么它能表达串行、并行和层级关系,但要自然表达条件分支、循环、错误处理或复杂变量传递,就需要额外扩展。神经网络式边可以自适应,但缺少精确控制。代码则天然支持 if、for、函数调用、异常处理和任意数据结构,因此更适合把 workflow 变成真实可执行对象。
AFlow 要搜索的不是一句提示词,而是一段能跑起来的流程程序。
形式化目标可以写成下面的式子:
在所有候选 workflow 组成的搜索空间中,找到让任务评估函数 在任务 上得分最高的 workflow。
这个公式的价值不在数学复杂度,而在它把“流程设计”变成了可比较的优化问题。过去人会说“这个 workflow 看起来合理”,AFlow 要求它真正执行、产生分数,并和其他候选 workflow 比较。这样,workflow 的好坏不再只依赖直觉,而依赖任务反馈。
不过,完整搜索空间太大。如果模型、温度、提示词、输出格式和边结构都任意变化,组合几乎没有上限。AFlow 因此做了一个工程化折中:固定模型、温度和输出格式,把搜索重点放在 提示词、代码边和算子 上。算子是预定义的常见流程模块,例如 Generate、Format、Review、Revise、Ensemble、Test、Programmer 和 Custom。它们相当于把前人经验变成可组合积木,让搜索不会完全从原子操作开始。
这里的“代码表示”还隐含一个很重要的约束:候选 workflow 不是只要语义上说得通就可以,它必须能通过统一接口被调用。也就是说,每个节点的输入输出要能被后续节点消费,成本要能被记录,错误要能被捕获,最终答案要能交给评估器。许多自然语言流程看起来完整,真正写成程序时会暴露出变量没有传递、输出格式不一致、异常分支没有处理等问题。AFlow 选择代码边,正是为了让这些问题在评估阶段变成可观测信号,而不是停留在描述层。
把工作流写成代码还有一个好处:它让“结构变化”和“提示词变化”可以同时被搜索。一个候选修改可能只是把数学答案提示词改得更严格,也可能是把原来的单路求解改成三路求解加投票,还可能是把代码生成结果送进测试算子,再根据失败信息修复。前两类变化在纯提示词优化里很难统一处理;在 AFlow 里,它们都表现为对同一个可执行 workflow 程序的修改,因此可以放到同一棵搜索树里比较。
这也解释了为什么论文没有把搜索空间完全交给 LLM 自由发挥。自由生成的流程可能很有创意,但不可运行的概率也高;过度限制的模板又会让系统只能微调人工预设。AFlow 的折中是:用节点、代码边和算子提供足够强的结构约束,同时允许 LLM 修改 prompt 和代码连接。对工程实践来说,这个折中比“让模型自己设计一个 agent”更可控,因为每次修改都必须落在接口、执行和评估可以接住的范围内。
AFlow 的候选 workflow 由多个提示词、代码表示的边和算子组合构成;模型、温度和输出格式等参数在实验中被固定,从而缩小搜索空间。
AFlow 方法总览:把 LLM 放进 MCTS 搜索闭环
AFlow 的整体结构可以看成三层。最底层是可执行 workflow,里面有节点、算子和代码边。中间层是评估器,它在验证任务上执行 workflow,返回分数、成本、错误日志和期望输出。最上层是搜索控制器,也就是 MCTS 变体;它决定从哪个已有 workflow 出发,让 LLM 优化器生成怎样的修改。
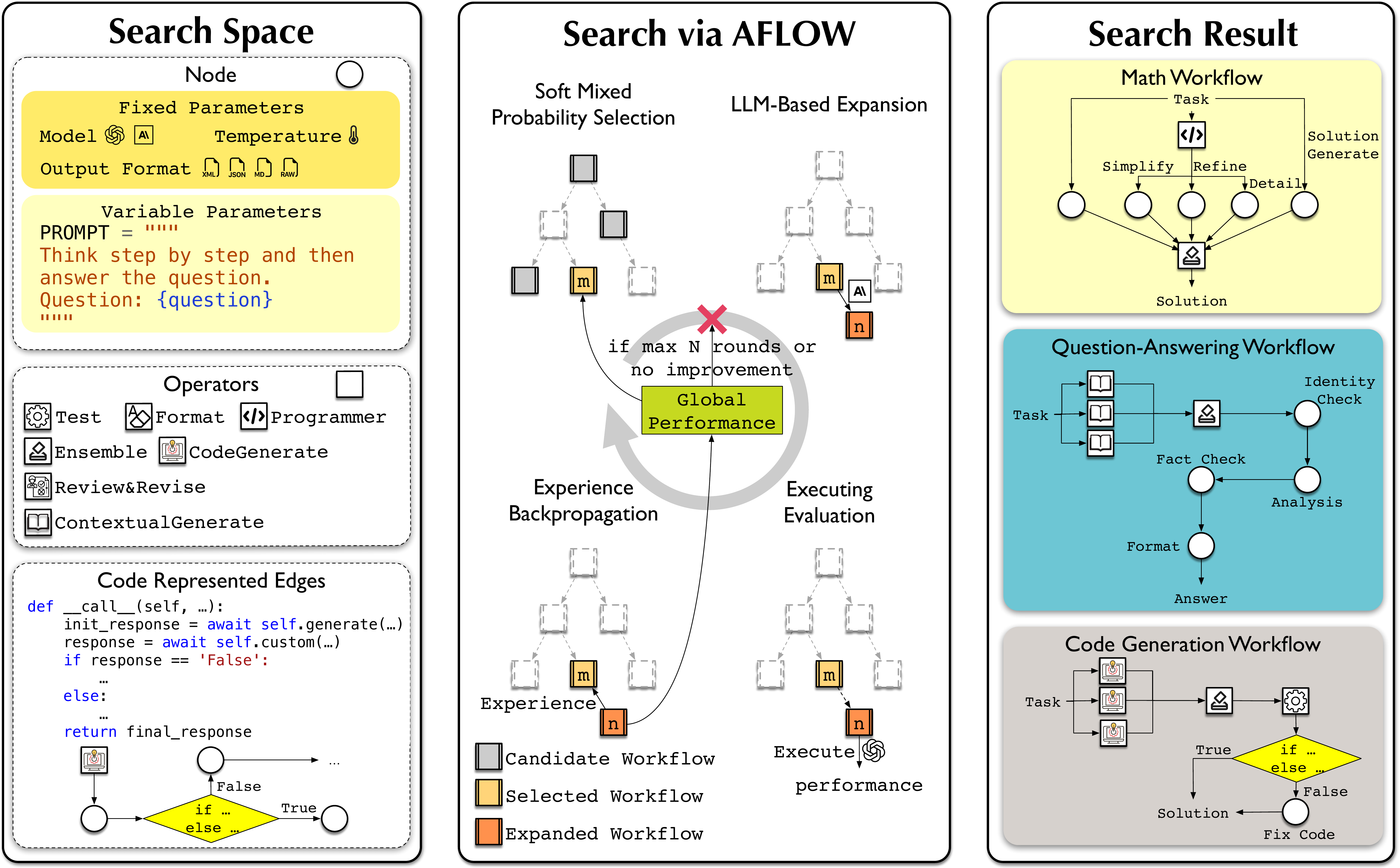
从搜索树中选择一个父 workflow,既考虑分数也保留探索
LLM 优化器读取父节点和历史经验,修改提示词、节点连接或算子组合
候选 workflow 在验证集上多次执行,得到分数、成本和日志
把修改、性能和成功/失败经验写回树结构,影响后续采样
这里最容易误解的一点是:AFlow 的 MCTS 树节点不是单个动作,也不是单个 LLM 调用,而是 完整 workflow。这意味着每个节点都可以独立执行和评分。树边代表“从父 workflow 到子 workflow 的一次修改”,例如新增 Programmer 算子、改变答案格式化提示词、加入 ensemble,或者移除某个无效 review 节点。
选择阶段使用软混合概率,而不是纯贪心。纯贪心会一直沿当前最高分节点扩展,很容易陷入局部最优;完全随机又浪费成本。AFlow 把均匀探索项和分数加权项混合起来:
是候选 workflow 数量, 是第 个 workflow 的分数, 是最高分; 控制探索比例, 控制分数差异对采样概率的影响。
扩展阶段由 LLM 优化器完成。附录中的优化器提示词要求模型参考当前 graph 和 prompt,做一次明确修改,可以增加、删除或调整节点、参数、提示词和代码边;同时要求输出完整正确,避免运行失败。这个提示词很工程化:它提醒模型可以使用 review、revise、ensemble、自问自答、条件和循环,但限制图复杂度不超过 10,防止候选 workflow 过度膨胀。
评估阶段是 AFlow 和纯语言自评之间的分界线。对推理任务,论文有明确的数值评估函数,所以每个候选 workflow 会在验证集上执行五次,计算均值和标准差。多次执行会增加单轮成本,但反馈更稳,能减少误判。随后,AFlow 把分数、修改内容、失败日志和预期输出作为经验回传给搜索树。
如果把这个闭环拆得再细一些,AFlow 每轮其实同时维护三种状态。第一种是 结构状态:当前 workflow 的代码、节点连接、使用了哪些算子、每个节点的提示词是什么。第二种是 评估状态:候选 workflow 在验证集上每次执行的分数、方差、成本和失败样例。第三种是 搜索状态:这个候选从哪个父节点来、这次修改是什么、它让分数上升还是下降、是否进入 top-k。三种状态缺一不可;只有结构没有评估,会变成代码生成;只有评估没有搜索树,会变成无记忆随机试错;只有搜索树没有可执行结构,又无法判断候选是否真实有效。
LLM optimizer 在这里扮演的是“提出修改”的角色,而不是最终裁判。它会读到父 workflow、局部经验和执行日志,然后尝试生成一个子 workflow。论文附录中的提示词要求优化器把单次修改包在结构化标签里,并且只生成当前图真正需要的自定义提示词,删除无用提示词。这种限制看似琐碎,实际很关键:如果优化器一次改太多,搜索树很难归因到底是哪一处导致提升;如果留下未使用提示词或空变量,候选 workflow 很容易运行失败。
经验回传也不只是把一个分数写回父节点。AFlow 会记录“相对父 workflow 的修改”以及“这次修改是否成功”。这使得下一轮扩展时,优化器能看到某条路径上哪些设计值得保留,哪些设计应该避开。例如在数学任务里,加入程序执行可能提升分数,但去掉审阅或过度强调格式可能导致退化。树结构把这种局部因果关系保存下来,让后续搜索更像沿着证据调整流程,而不是在长上下文里凭印象继续改。
还有一个容易忽略的设计是从初始 workflow 重新探索的能力。AFlow 的选择策略不只偏向高分节点,也允许初始模板在任意轮次重新被选中。这一点对巨大代码空间很重要,因为早期某个高分分支可能只是局部最优;如果搜索永远围绕它微调,就可能错过另一类完全不同的流程。保留空模板入口,相当于给搜索树保留“重新开一条路”的机会。
把这四个阶段连起来看,AFlow 的反馈闭环其实有两层。第一层是外层的搜索反馈:候选 workflow 被执行后产生分数,分数改变搜索树中各节点被选择的概率。第二层是内层的语义反馈:错误日志、期望输出和修改说明进入优化器上下文,影响下一次生成的代码和提示词。前者告诉系统“往哪条路径走”,后者告诉模型“为什么这条路径好或坏”。如果只有第一层,搜索会像黑箱优化,缺少解释和针对性;如果只有第二层,模型会有解释但没有全局探索策略。AFlow 把两层合在一起,才形成可持续改进。
这也说明为什么论文要多次执行同一个候选 workflow。LLM 输出本身有随机性,某个 workflow 单次表现好可能只是偶然命中样本,单次表现差也可能来自一次异常输出。五次执行虽然增加成本,却让反馈更接近候选结构的真实期望表现。对搜索算法来说,噪声较小的分数比便宜但不稳定的分数更有用,因为错误反馈会误导父节点选择和经验回传。
核心机制:算子、树结构经验与执行反馈
AFlow 的第一类机制是 operators。算子不是论文为了好看引入的名词,而是搜索效率的关键。比如 Generate 负责生成,Format 负责规范答案,Review 和 Revise 负责审查与修订,Ensemble 负责从多个答案中选择,Test 负责运行公开测试,Programmer 负责生成并执行 Python 代码。它们把常见 agent 步骤封装成稳定接口,减少 LLM 每轮都从零设计的负担。
1class Workflow:2 async def __call__(self, problem: str):3 solution = await self.custom(problem, instruction=prompt_custom.GENERATE)4 reviewed = await self.review(problem=problem, solution=solution)5 revised = await self.revise(problem=problem, solution=solution, feedback=reviewed)6 return revised, self.llm.cost_manager.total_cost这段简化伪代码表达了 AFlow 的工程直觉:workflow 是一个可执行函数,算子是函数里的可复用调用,成本管理器记录实际开销。LLM 优化器要做的不是“口头建议可以加 review”,而是修改这段可运行结构,让评估器能真正执行。
第二类机制是 树结构经验。现有自动优化方法常把所有历史尝试按时间顺序塞进 prompt。问题是,历史越长,模型越难判断某次修改发生在哪个父 workflow 上,也难以区分“这个修改在 A 路径有效,但在 B 路径无效”。AFlow 的树结构把每个 workflow、分数、修改说明、成功和失败子节点保存在父子关系里,因此经验更有上下文。
线性历史
把过去尝试按顺序列给 LLM。优点是简单,缺点是不同分支的经验容易混在一起,长上下文会造成信息丢失。
树结构经验
每个 workflow 是一个树节点,修改挂在父节点下面。优化器能沿成功路径继续,也能回到父节点避开失败分支。
第三类机制是 执行反馈。论文附录展示了具体例子:在 MATH 任务上,某轮提示词加入“用 boxed LaTeX 给出最终答案”后,系统更容易抽取最终答案;另一轮虽然要求答案简洁,却可能因为过度关注格式而削弱推理,导致分数下降。这类细节很难靠人工直觉一次写对,但执行日志可以告诉优化器哪些样例错了、期望输出是什么、修改后是否真的提升。
这些机制之间是互相咬合的。算子提供可复用的搜索积木,代码边让 workflow 可执行,执行反馈提供真实评分,树结构把评分和修改绑定到路径上。少掉任何一个,AFlow 都会更像“让 LLM 随机改 prompt”:可以试,但很难系统进步。
从算子的角度看,AFlow 并不是把人工知识完全拿掉,而是把人工知识放在更合适的位置。Generate、Review、Revise、Ensemble、Test、Programmer 这些算子都来自已有 agent 工作流里的常见成功模式。论文承认 operators 是一种人类设计努力,但它不是最终流程,而是搜索空间里的可用动作。最终是否使用某个算子、放在哪个位置、和哪些提示词组合,仍然要由搜索和评估决定。
这个区别对复用很重要。假设你在做一个客服问答 agent,可能没有 Programmer 算子,但会有检索、意图识别、政策校验、人工升级等算子。AFlow 的启发不是照搬论文的七个算子,而是先把领域中稳定可复用的操作封装成接口,再让搜索决定如何组合。算子太少,搜索会在原始代码空间里浪费大量尝试;算子太强或太死,又会把模型锁在人工预设路径里。好的算子应该提供“常见有效动作”,而不是提前规定完整答案。
树结构经验还解决了另一个实际问题:失败经验也有价值。在线性历史里,失败尝试经常只是变成长 prompt 里的噪声;在树结构里,失败会带着父节点和修改说明被记录。后续优化器可以知道“在这个父 workflow 上移除程序执行会下降”“在那个父 workflow 上加入格式化会提升”。这种失败定位对复杂工作流尤其关键,因为同一个模块在不同上下文中的作用可能完全不同。
执行反馈则让 AFlow 具备“指标意识”。例如问答任务的 F1 会奖励最终答案字符串与参考答案的重合,代码任务的 pass@1 会奖励一次生成可通过测试,数学任务的求解率会奖励最终数值正确。不同指标会推动不同 workflow 形态:问答可能更重视答案压缩和格式化,代码更重视测试与修复,数学更重视中间推理和最终答案抽取。AFlow 通过真实指标反馈,让流程结构逐步向任务评价方式靠拢。
还要注意,执行反馈不是只给一个总分。附录里的树结构经验会记录具体修改和失败方向,例如移除程序员算子导致数学任务下降,简化生成过程导致审阅链断掉,或者增加最终答案格式要求带来提升。这类反馈能让 LLM optimizer 在下一轮生成时有更细的参照:不是泛泛地“提高准确率”,而是知道哪些模块、提示词或信息传递方式和分数变化有关。对复杂 agent 来说,模块之间的相互作用往往比单个模块本身更重要,AFlow 的经验格式正是为了保留这种相互作用。
算法与实现细节
正文算法把 AFlow 压缩成一个清晰闭环。它的输入是评估器 、数据集 和算子集合 ,输出是优化后的 workflow 。附录详细版本还加入初始 workflow、最大轮数、top-k、早停轮数等参数。
1Require: Evaluator , Dataset , Operators 2Ensure: Optimized Workflow 3Initialize , split into and 45for iteration to :6 Select(tree) # Using soft mixed probability strategy7 Expand(, ) # LLM-based expansion8 Evaluate(, , ) # Multiple runs for robustness9 Backpropagate(, ) # Update experience and scores10 Update if improved11 if ConvergenceCriteriaMet():12 break13return 这段算法展示 AFlow 的主循环:从模板 workflow 出发,反复选择父节点、扩展子 workflow、执行评估、回传经验,并在性能提升时更新最优 workflow。
初始化不是随便给一个空 prompt。AFlow 从模板 workflow 开始,这个模板提供节点和算子的调用框架。搜索前,数据集会按 20% 验证集和 80% 测试集划分,随机种子固定为 42。论文还会让空模板在验证集上执行五次,从中选择分数方差较高的问题作为最终验证集。这一步的直觉是:验证集最好能区分 workflow 的差异,而不是所有候选都轻松答对或全部失败。
选择阶段调用 Select(tree),根据软混合概率从候选 workflow 中选父节点。这里既包括 top-k 高分 workflow,也保留初始 workflow 的探索机会。这个设计很微妙:如果只从高分节点出发,搜索可能很快收敛到局部结构;如果允许从空模板重新开始,LLM 仍有机会发现完全不同的路径。
扩展阶段调用 Expand(workflow, O)。优化器读取父 workflow 的代码、提示词、历史修改、成功和失败经验,再生成一个子 workflow。它可以改 prompt,也可以改节点连接,还可以加入或移除算子。论文要求候选输出完整可运行,这一点让后续评估不只是文本比较,而是真正执行程序。
评估阶段调用 Evaluate(child.workflow, G, D_V)。每个新 workflow 会在验证集上执行五次,以均值和标准差衡量表现。对 HumanEval 和 MBPP,这可能意味着生成代码并用测试衡量 pass@1;对 GSM8K 和 MATH,是 Solve Rate;对 HotpotQA 和 DROP,是 F1。评估结果还包括成本和错误日志,后者会进入下一轮优化上下文。
回传阶段调用 Backpropagate(child.workflow, score)。AFlow 记录三类信息:workflow 的分数,优化器相对父 workflow 做了什么修改,以及这次修改相对父节点是否成功。随后它把这些信息写回搜索树,并把分数加入全局记录,供下一轮选择使用。早停条件则用于控制成本:如果 top-k workflow 的平均分连续若干轮没有提升,搜索提前结束。
附录实现还补充了三个重要接口。ActionNode 负责把一次 LLM 调用封装为节点,并支持 raw、json、markdown、xml 等输出 schema;Workflow 类把任务数据集、LLM 实例和成本管理器放到统一可执行对象里;Operators 则实现 Generate、Format、Review、Revise、Ensemble、Test、Programmer 等复用模块。理解这些接口后,AFlow 就不再只是算法图,而是一套可以落地的 workflow 搜索框架。
从工程角度看,ActionNode 的 schema 设计不是小细节。JSON、Markdown、XML 和原始文本分别对应不同的约束强度。代码生成时 Markdown 往往更适合承载代码块;结构化抽取或中间状态传递时 JSON 更容易被程序解析;需要强约束标签时 XML 可能更稳定。AFlow 把输出格式作为节点参数的一部分,说明 workflow 优化不仅是“提示词写什么”,也包括“中间结果用什么协议交给下一步”。
Workflow 基类里的成本管理器也值得注意。很多 agent 系统只看准确率,但多节点流程会迅速放大调用成本。AFlow 在每个候选 workflow 上记录总成本,使得后续可以画出成本-性能前沿。这样,搜索结果不只是“最高分 workflow”,还可以被部署者按预算选择:有时稍低一点的分数、低很多的成本,才是工程上的更优方案。
附录中的完整算法还把 SelectParent、CalculateMixedProbabilities、Optimizer 和 Executor 分开写出。这个拆分提示了一个可替换设计:你可以换掉父节点选择策略,可以换掉 LLM 优化器,可以换掉执行模型,也可以换掉评估器。AFlow 的核心不是某个固定实现,而是“可执行候选 + 搜索树经验 + 真实评估反馈”的接口组合。只要这些接口稳定,具体模型和任务都可以替换。
不过,AFlow 的算法也有明确代价。每个候选 workflow 要执行五次验证集评估,搜索又要持续多轮,因此它不适合一次性、低价值、没有复用机会的小任务。它更像是在为一类任务训练或发现一个可反复使用的流程模板。搜索阶段花费的成本,需要在后续大量执行中摊销;如果只运行一两次,直接手写简单流程可能更划算。
早停条件同样体现了成本意识。top-k 平均分连续若干轮不提升,说明当前搜索在已有空间里难以继续找到明显改进,此时继续执行候选 workflow 可能只是消耗预算。这个判断并不保证已经找到全局最优,但在工程上给出一个可操作的停止点:当最好的一批流程稳定下来,且新增修改不能带来收益,就把当前最优 workflow 作为输出。
如果把 AFlow 写成可复现系统,最容易漏掉的是“版本化”。每个候选 workflow 都应该有版本编号、父节点编号、修改摘要、执行数据切分、模型配置、成本和日志。否则即使最后得到一个高分流程,也很难解释它从哪里来,更难在任务变化后继续优化。论文的树结构经验实际上就是一种 workflow 版本控制:它不只保存最终代码,还保存从父版本到子版本的演化关系和性能证据。
另一个实现细节是验证集和测试集的角色必须分清。AFlow 用验证集选择和优化 workflow,最终测试集用于报告性能。如果在搜索过程中不断看测试集,系统就会把工作流调到测试集上,结果失去泛化意义。论文按一比四划分数据,并在验证集里选择方差较高样本,意图是让搜索阶段有足够分辨力,同时保留独立测试来评估最终流程。
实验结果怎么读
实验覆盖六个基准:HotpotQA 和 DROP 代表问答,HumanEval 和 MBPP 代表代码,GSM8K 和 MATH 代表数学推理。指标也按任务变化:问答用 F1,代码用 pass@1,数学用 Solve Rate。这个设置比较合理,因为 AFlow 声称优化的是通用 workflow 结构,而不是某个单一任务技巧。
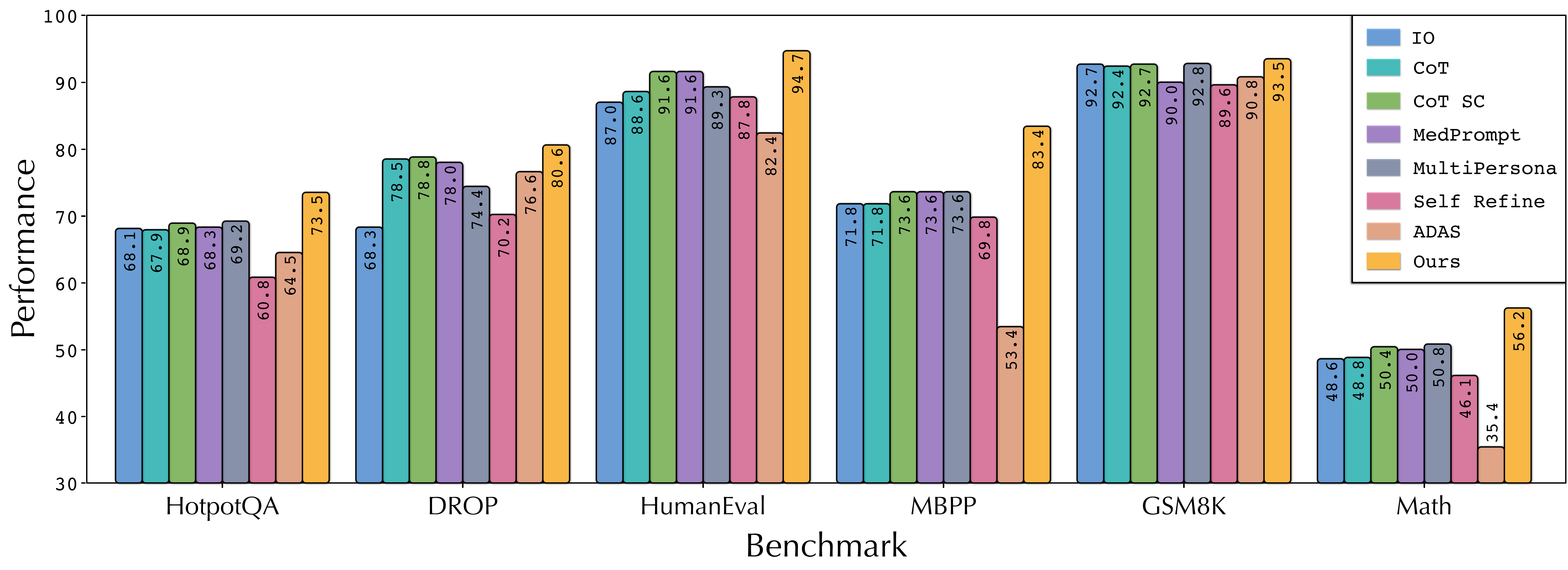
主结果表里,GPT-4o-mini 执行下 AFlow 在六个数据集上的结果分别是 HotpotQA 73.5、DROP 80.6、HumanEval 94.7、MBPP 83.4、GSM8K 93.5、MATH 56.2,平均 80.3。相比手工方法,平均提升 5.7%;相比 ADAS,平均提升 19.5%。尤其在 MATH 和 MBPP 这类更难任务上,论文强调相对 ADAS 的提升达到 57%,说明树结构经验和执行反馈在复杂 workflow 中更有价值。
读这个结果时,要避免一个误解:AFlow 不是证明“任何自动搜索都比人强”。它证明的是,在有明确验证任务、能执行候选 workflow、能记录反馈的场景下,MCTS 式搜索能系统探索许多人工未必会手动尝试的流程结构。它也不只是让模型更强,因为执行模型仍是 GPT-4o-mini;收益主要来自 workflow 结构变化。
第二张表检验跨模型迁移。论文用 GPT-4o-mini 和 DeepSeek-V2.5 作为执行模型分别搜索 workflow,然后把 workflow 放到 GPT-4o-mini、DeepSeek-V2.5、GPT-4o 和 Claude-3.5-sonnet 上测试。多数情况下,AFlow workflow 比基线更强,说明流程结构有一定泛化性。但也出现一个有意思现象:DeepSeek 搜出的 workflow 在 GPT-4o-mini 上明显弱于 GPT-4o-mini 自己搜出的 workflow。这提醒我们,workflow 和模型能力是耦合的。
基线选择也值得看。IO 是直接调用,CoT 是单流程推理,CoT-SC 是多答案自一致性,MedPrompt 和 MultiPersona 是更复杂的人设或投票流程,Self-Refine 是迭代修订,ADAS 是自动 workflow 设计方法。AFlow 超过这些基线,说明它并不是只学到某个固定技巧,而是在不同任务上找到不同流程组合。
六个数据集的组合让实验结论更有说服力。HotpotQA 和 DROP 都是问答,但它们对推理和答案抽取的要求不同;HumanEval 和 MBPP 都是代码生成,但前者更偏函数级编程能力,后者有更多基础程序题;GSM8K 和 MATH 都是数学,但 MATH level 5 难度明显更高。AFlow 在这些任务上都有效,说明它学到的不是某个数据集的题型捷径,而是能够根据任务反馈调整流程。
指标也会影响如何理解结果。F1 对问答任务很敏感,最终答案表达、冗余文字和格式都会影响分数;pass@1 对代码任务很严格,候选代码只要一个关键边界条件错了就可能失败;Solve Rate 则要求数学题最终答案正确。AFlow 的优势在于,它可以为这些指标分别发现合适的结构:问答中加强格式化,代码中加入测试和修复,数学中引入程序辅助、逐步推理或答案规范化。
手工基线代表的是几类常见人工经验。CoT 让模型显式推理,CoT-SC 用多答案投票提升稳定性,Self-Refine 通过反馈修订,MultiPersona 用多角色视角增加多样性,MedPrompt 结合多答案和投票。它们都有效,但结构固定。AFlow 的比较对象不是一个弱基线,而是一组经过实践验证的流程模式;它能超过这些方法,说明自动结构搜索确实找到了更贴合任务和执行模型的组合。
ADAS 的对比则更直接。ADAS 也是自动设计 workflow,但论文指出它使用线性启发式搜索,把所有历史工作流放入提示词中,容易出现信息损失和经验混杂。AFlow 相对 ADAS 的平均提升说明,自动化本身不是充分条件;关键还在于如何组织搜索历史、如何选择父节点、如何把执行反馈绑定到具体修改上。
跨模型实验还给出一个实践提醒:不要把 workflow 当作完全模型无关的资产。一个流程在强模型上可能依赖模型本身的推理能力,在弱模型上就需要更多分解、测试或修复;反过来,弱模型搜索出的流程可能过度补偿某些能力短板,迁移到强模型后不一定最优。因此部署时最好把“任务、模型、预算、指标”一起看,而不是只迁移论文里最高分的流程。
主结果还可以从“任务族”角度理解。问答任务中,AFlow 的收益说明自动流程能改善信息整合和答案表达;代码任务中,收益说明测试、集成和修复这类结构比单次生成更可靠;数学任务中,收益说明程序辅助、逐步解题和最终答案抽取可以共同作用。六个 benchmark 放在一起,实际上是在问同一个问题:当任务需要多个中间步骤时,自动搜索能否找到比人类固定套路更适合当前模型的步骤组合。AFlow 的平均提升就是对这个问题的正面回答。
不过这些数字也不能被过度外推。论文中的任务都有自动评分或相对明确的评价方式,且候选 workflow 可以离线执行许多次。如果换成实时交互、长期记忆、工具权限复杂或安全约束很强的环境,评估反馈就不一定这么干净。此时 AFlow 的思想仍有价值,但需要先把任务拆成可离线回放的小评估集,并为危险工具调用设置模拟器或沙箱。
另外,实验报告的是划分测试集上的平均表现,不等于每个样本都会更好。工作流越复杂,越可能在少数样本上引入额外失败点,例如中间格式解析错误、测试样例误导、集成选择失误或答案过度压缩。因此上线时仍需要查看失败类型,而不能只看平均分。更稳妥的做法是保留按任务、按错误类别和按成本区间拆分的评测面板,持续复查。
消融、成本与案例:哪些设计真的起作用
成本分析是这篇论文比较实用的一部分。很多 agent workflow 都会提高性能,但代价是多次模型调用,部署时不一定划算。AFlow 的成本-性能图把不同执行模型和 workflow 放在同一帕累托前沿上比较,展示哪些组合能以更低成本达到更高或相近表现。
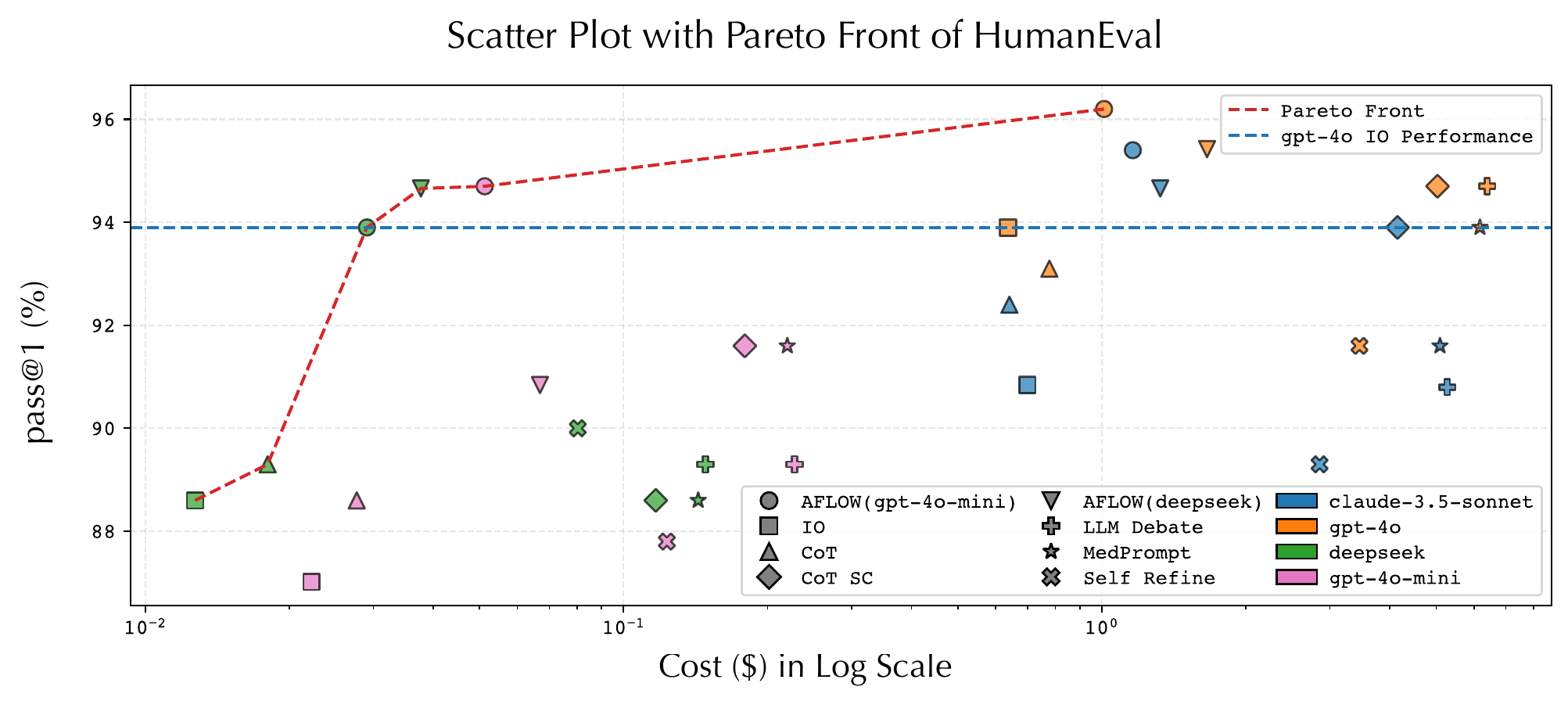
论文给出的关键数字是:AFlow 用 GPT-4o-mini 搜到的 workflow,改用 DeepSeek 执行时,可以以 GPT-4o IO 约 4.55% 的成本达到相近表现;AFlow 用 DeepSeek 搜到的 workflow,改用 GPT-4o-mini 执行时,也能以约 6.78% 的成本接近 GPT-4o IO。这个结果的含义不是“弱模型一定能超过强模型”,而是“正确流程可以显著放大便宜模型的任务能力”。
消融研究关注 operators。论文把 operators 视为人类设计努力,因为它们把常见成功模式提前封装进搜索空间。GSM8K 结果显示,带 operators 的 AFlow 能更快发现更好 workflow,并呈现多次小幅提升。更有意思的是,不带预定义 operators 时,AFlow 仍然达到 93.1%,超过手工设计方法,并自发形成类似 ensemble 和格式化的结构。
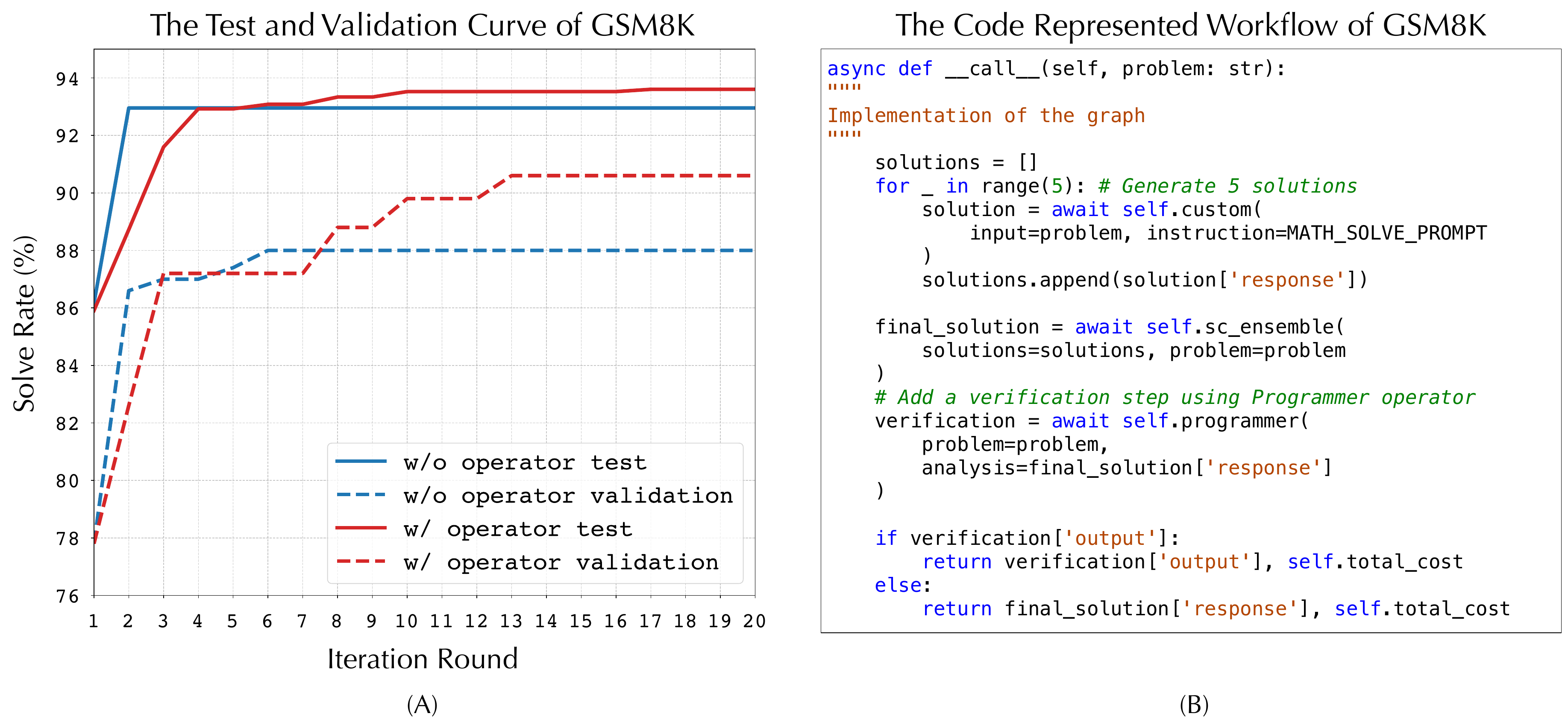
这个消融给出一个平衡判断:operators 有用,但不是 AFlow 的全部。它们像搜索先验,能提高有效改进的概率;但即使没有它们,代码表示和 LLM 扩展也能让系统从空模板中逐步形成流程。这对复用很重要,因为换到新任务时,我们不一定一开始就知道该封装哪些算子,可以先用 Custom 和基础代码结构运行,再把常见成功模式抽成算子。
案例研究把树结构经验讲得更具体。GSM8K 上,AFlow 从只有单个节点且没有提示词的空模板出发,逐步添加 Programmer、ScEnsemble、逐步解题提示、答案格式化等结构。有些分支失败了,例如某轮加入自定义 review 节点直接修改复杂过程生成的答案,反而降低准确率;另一轮过度关注题目里的 discount 信息,也导致退化。
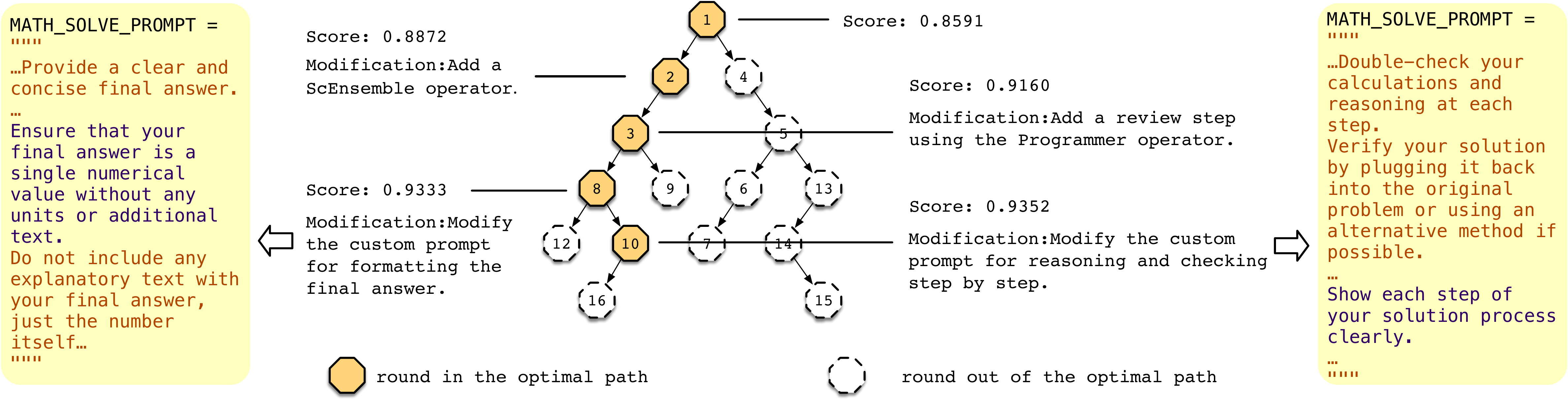
树结构的好处在这里很直观:失败修改不会污染所有历史,而是留在某个分支上;成功路径可以继续被扩展;优化器能看到“从第 1 轮到第 2 轮增加 Programmer 提升了分数”“从第 2 轮到第 3 轮加入 ScEnsemble 又提升了分数”。这种局部、带父节点上下文的经验,比一大段线性日志更适合指导下一次修改。
成本结果还可以换个角度读:AFlow 搜索阶段本身并不便宜,但它可能发现一个长期运行更便宜的执行流程。比如某个工作流用便宜模型多做几步,最终超过昂贵模型的一次直接调用;如果这个任务会被调用很多次,搜索成本就能被摊薄。反之,如果任务只运行少量样本,或者评估本身昂贵,那么 AFlow 的搜索成本可能压过收益。
消融中的“无算子仍然有效”也需要细读。它并不表示算子没有价值,而是说明代码表示和 LLM 优化器有能力从基础自定义节点中发现结构。带算子版本更高效,说明人工先验能显著缩短搜索路径;无算子版本达到 93.1%,说明 AFlow 没有完全依赖人工封装。两者合起来给出的结论是:算子是加速器,不是唯一发动机。
GSM8K 案例里的失败分支很有启发。某些修改看起来合理,例如加入 review 或重述问题,但实际可能因为破坏了已有信息流而降分。AFlow 能记录这些失败,让后续搜索回避类似方向。这对现实 agent 系统也常见:一个模块单独看有用,放到完整流程里可能引入冗余、冲突或格式漂移。只有端到端执行评估才能发现这种系统层面的副作用。
MBPP 案例说明 AFlow 可以演化出类似 AlphaCodium 的结构:多路代码生成、集成选择、额外测试、失败修复。HotpotQA 案例则说明答案格式化也可能成为关键步骤,因为问答指标不只看推理是否正确,也看最终答案是否简洁准确。MATH 案例显示程序执行和最终答案格式对数学任务有帮助。这些案例共同说明,AFlow 不是寻找一个万能流程,而是在不同任务上发现不同的工程套路。
因此,读消融和案例时,最该带走的不是某个具体 workflow,而是“如何让系统知道哪个模块有用”。AFlow 的做法是把每次结构变化、分数变化和失败日志绑定起来。一个团队如果想复用这篇论文,可以先从日志体系做起:记录每次 workflow 版本、输入样本、输出结果、成本、错误类型和相对上一版的修改。没有这些记录,即使引入搜索算法,也很难判断改动是否真的有效。
成本前沿还提供了一个选择 workflow 的实际方法。部署时不一定选择最高分点,而要看是否存在被支配的方案:如果一个流程比分数更低的流程更贵,那它就不值得选;如果一个流程分数略低但成本大幅下降,可能反而是生产环境里更好的选择。AFlow 能把多个候选流程放到同一张成本-性能图上,让“用强模型一步完成”与“用便宜模型多步完成”可以公平比较。
案例中的树形轨迹也说明,workflow 搜索不是单调上升的。某些轮次会下降,某些修改会失败,甚至看起来聪明的结构也会破坏已有流程。这一点反而让结果更可信:真实系统优化本来就会出现退化。AFlow 的关键不是避免所有失败,而是让失败可定位、可回退、可进入经验库。这样的失败会成为后续搜索的边界,而不是单纯浪费掉。
附录实现、开放式任务与复用启发
附录对工程复现很有价值。ActionNode 展示节点如何接收上下文、LLM 和输出 schema;Workflow 类展示候选流程如何作为可执行对象保存数据集、LLM 和成本管理器;Operators 代码展示生成、代码生成、格式化、审阅、修订、集成、测试和程序员算子的接口。读到这里可以发现,AFlow 的核心不是某个复杂数学技巧,而是把 agent 流程工程化到足够可搜索。
workflow 映射到代码的例子尤其重要。示例先生成三个代码解,再用自一致性集成选出最佳解,然后运行测试;如果测试失败,就把问题、失败解和错误传给修复提示词。这正是许多人工代码 agent 的套路,但 AFlow 的价值在于它能把这类套路作为搜索结果自动发现、修改和评估。
论文还讨论了开放式任务。正文实验依赖明确数值指标,但真实世界里很多任务没有标准答案,例如长篇小说生成、研究想法生成或创意写作。为此,作者修改 workflow 优化提示词,移除只适合推理题的约束,并引入 LLM-as-a-Judge 评估器,从内容相关性、质量、连贯结构和参考比较四个维度打分。
开放式案例有两个。长篇小说生成要求写一篇约 20000 词、围绕“遗憾影响时间流速”的小说。直接 Claude-3.5-sonnet 基线拒绝生成完整小说,只给写作建议;AFlow 八轮后学到“先大纲、再角色档案、再逐章生成”的 workflow,生成约 27000 词文本,第 8 轮人类平均分 19.3、排名第一。学术想法生成案例中,AFlow 六轮后形成“生成多个想法、选择、展开、评估、修订”的流程,第 6 轮人类分 19.1、排名第一。
这些开放式结果应谨慎看待。LLM-as-a-Judge 不是客观真值,人工评分样本也有限;但它们说明 AFlow 的搜索闭环可以迁移到没有传统准确率的任务,只要能构造一个相对稳定的评价信号。工程上,如果要复用到开放任务,最好先设计小规模人工校准集,检查评价器是否和人类偏好一致,再让 AFlow 大规模搜索。
理论性质部分给了三个边界。搜索空间完备性依赖代码边能表达有效节点关系,以及 LLM 扩展有非零概率生成有效修改。收敛性质依赖评估函数有界、代码边保持 workflow 有效、LLM 有非零概率产生改进。搜索效率来自 operators、树结构经验和执行反馈。这些条件都不是免费的:如果任务没有可靠评估函数,或者候选 workflow 经常运行失败,AFlow 的优势会明显下降。
因此,AFlow 最适合的场景是:任务可以自动打分,workflow 可以反复执行,单次搜索成本可以被后续复用摊销,且你确实需要探索流程结构而不是只改一句 prompt。对工程读者来说,最可迁移的启发是 把 agent 设计从“写提示词”升级为“管理可执行流程和反馈数据”。一旦 workflow 能被表示、运行、记录和比较,搜索、回放、消融和自动优化才真正有落点。
如果要把 AFlow 迁移到自己的项目,可以先判断四个问题。第一,任务是否有稳定评估信号;如果没有,能否构造人工抽样、规则检查或评审模型。第二,流程是否能被代码化;如果步骤只能靠人读上下文临时判断,就很难搜索。第三,候选失败是否安全;如果一次错误会造成真实损失,就需要沙箱、回放数据和离线验证。第四,搜索出的 workflow 是否会被重复使用;只有复用次数足够多,搜索成本才值得。
不同任务上的复用边界也不同。代码生成适合 AFlow,因为测试和执行反馈明确,失败样例能直接指导修复;数学推理也适合,因为最终答案可判定,并且程序辅助和格式化能显著改变结果。开放问答适合但要小心,答案匹配指标可能奖励格式而不完全奖励事实可靠性。创意写作和研究想法生成最难,因为评价信号主观,LLM-as-a-Judge 容易偏向流畅表达,需要人工校准来避免搜索迎合评审模型。
最后,AFlow 对 agent 工程的最大提醒是:流程优化不应该只发生在脑子里或文档里。真正可改进的 agent 系统需要把流程版本、执行轨迹、评估结果和成本都结构化保存。这样,无论你使用 MCTS、贝叶斯优化、进化搜索,还是更简单的人工迭代,都能建立“改动到结果”的证据链。AFlow 的贡献就在于把这条证据链组织成可自动搜索的闭环,并用实验说明它在多类任务上确实能找到比手工经验更强的流程。
从产品落地角度,AFlow 还提示我们要把“搜索时环境”和“上线时环境”分开。搜索阶段可以使用较强优化模型、更多验证运行和更详细日志;上线阶段则可以只保留搜索出的执行 workflow,用更便宜的执行模型运行。论文中的成本分析正是这种思路:昂贵模型不一定承担每次用户请求,它可以承担离线设计和优化角色,最终服务请求的是被优化后的流程。
另一个边界是人类可解释性。AFlow 输出的是代码 workflow,比纯自然语言策略更可审计,但它仍可能生成复杂提示词和多节点结构。如果团队要在高风险领域使用,需要给每个节点、算子、评估指标和失败回退策略加上人工可读说明,并保留禁用或替换某个模块的能力。自动搜索能加速发现流程,却不能替代对权限、安全和责任边界的工程治理。
把这些边界合在一起看,AFlow 更像一套“流程实验平台”,而不是拿来即用的万能 agent。它要求任务能被批量回放,要求结果能被评分,要求候选流程能安全失败,也要求团队愿意维护算子库和日志库。满足这些条件时,它可以把许多原本靠资深工程师经验完成的流程调参,变成可审计、可复跑、可比较的系统优化过程。