Title
AFlow: Automating Agentic Workflow Generation
题目:AFlow:自动化生成智能体工作流。
Authors
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, Chenglin Wu
作者包括 Jiayi Zhang、Jinyu Xiang、Zhaoyang Yu、Fengwei Teng、Xiong-Hui Chen、Jiaqi Chen、Mingchen Zhuge、Xin Cheng、Sirui Hong、Jinlin Wang、Bingnan Zheng、Bang Liu、Yuyu Luo 和 Chenglin Wu。
Institutions
1. DeepWisdom 2. The Hong Kong University of Science and Technology (Guangzhou) 3. Renmin University of China 4. Nanjing University 5. Fudan University 6. King Abdullah University of Science and Technology 7. Université de Montréal & Mila 8. The Hong Kong University of Science and Technology
机构包括 DeepWisdom、香港科技大学(广州)、中国人民大学、南京大学、复旦大学、阿卜杜拉国王科技大学、蒙特利尔大学与 Mila,以及香港科技大学。
摘要
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code is available at https://github.com/FoundationAgents/AFlow.
大语言模型已经在多个领域的复杂任务中展现出很强能力,通常依靠包含详细指令和操作顺序的 agentic workflow 来完成任务。然而,构建这些 workflow 需要大量人工投入,限制了可扩展性和泛化能力。为解决这一问题,论文把 workflow 优化重新表述为代码表示的搜索问题:调用 LLM 的节点通过边连接。作者提出 AFlow,用蒙特卡洛树搜索在该空间中高效发现高性能 workflow,并在六个基准上证明其有效性;相对于当前最强基线平均提升 5.7%,并且能让小模型在部分任务上超过 GPT-4o,同时推理成本只有 GPT-4o 的 4.55%。
引言
Introduction
引言
Large Language Models (LLMs) have emerged as powerful tools for solving complex tasks across various domains, including code generation, data analysis, decision-making, and question answering~[cite: DBLP:journals/corr/abs-2408-05109, bo2024nlsql, DBLP:journals/corr/abs-2406-07815, yu2024hai, sun2024chatbot, wangchain, song2023llm, xietravelplanner, li2024debug]. However, the rapid advancement of LLMs heavily relies on manually designed agentic workflows -- structured sequences of LLM invocations accompanied by detailed instructions. Designing and refining these workflows requires significant human effort, which limits the scalability and adaptability of LLMs to new, complex domains and hinders their ability to transfer skills across diverse tasks~[cite: DBLP:conf/cidr/0001YF0LH24].
大语言模型已成为代码生成、数据分析、决策和问答等复杂任务中的重要工具。许多应用依赖 agentic workflow,也就是由多次模型调用、指令和操作顺序构成的执行流程。但这些流程通常由人设计,迁移到新任务时成本高、适应慢。
Recent efforts have focused on automating the discovery of effective agentic workflows to reduce the reliance on human intervention~[cite: omar2024dspy, mert2024text,liu2023dynamic,hu2024automated]. Despite these advancements, full automation has not been achieved. For instance, omar2024dspy requires manual workflow setup before automated prompt optimization. Similarly, methods proposed by mert2024text and zhuge2024gptswarm fail to capture the full diversity of workflows necessary for a wide range of tasks~[cite: yu2023thought, yang2024buffer, sun2023indeterminacy], as their optimization objectives struggle to represent the breadth of possible workflows. The inability to effectively model diverse workflow structures within these automated systems limits their utility and impact. ADAS~[cite: hu2024automated] represents workflows using code, achieving a relatively complete representation. However, due to the efficiency limitations of its linear heuristic search algorithm, ADAS struggles to generate effective workflows within a limited number of iterations. This highlights the need for more effective techniques to represent and automate the generation of agentic workflows, which would accelerate the application of LLMs across domains.
近期研究尝试自动发现有效的 agentic workflow,以减少人工介入。虽然已有方法取得进展,但完整自动化仍未实现:有的方法需要人工先写出初始 workflow,有的方法主要优化提示词或少量超参数,难以覆盖多节点、条件分支、工具调用和复杂依赖构成的结构空间。
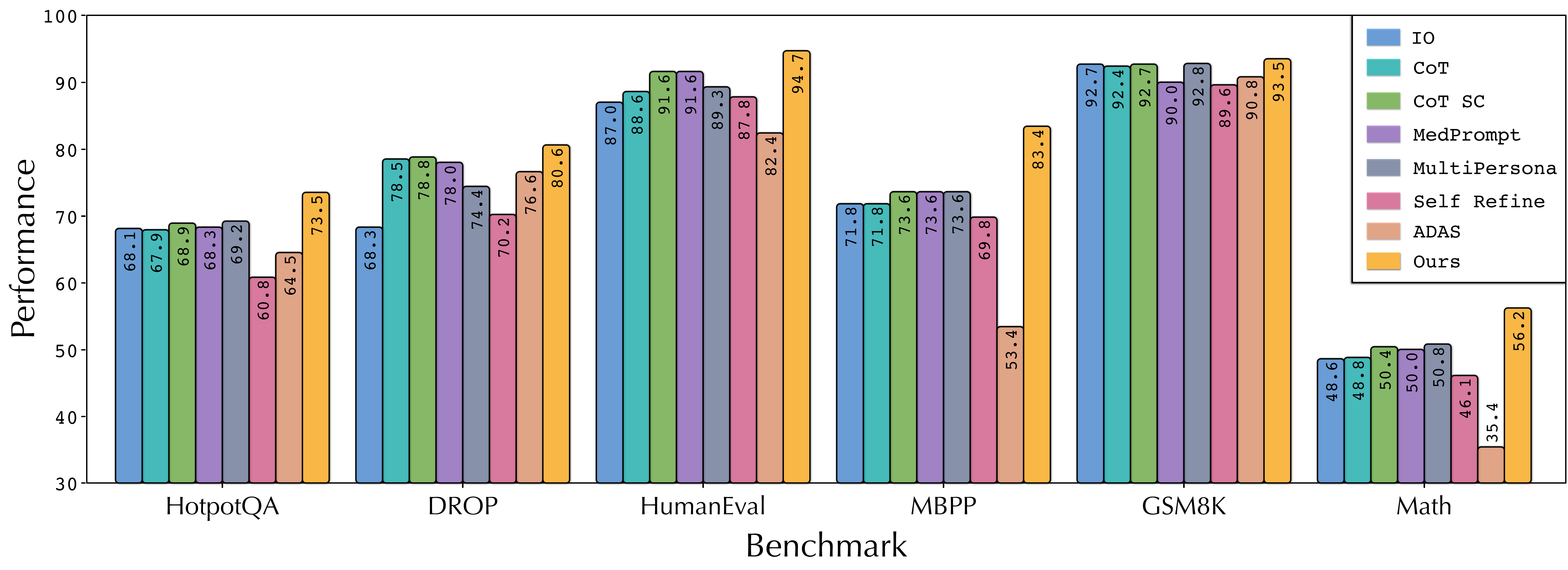
这张图比较 AFlow 与其他方法在不同数据集上的表现。数学任务使用 Solve Rate,代码任务使用 pass@1,问答任务使用 F1。图中核心信息是:AFlow 在六类基准上整体更稳定,尤其在需要流程组合和执行反馈的任务上,自动搜索出的 workflow 能超过手工设计或其他自动优化方法。
In response to these challenges, we introduce an innovative framework for automatically generating agentic workflows. Our key idea is to model the workflow as a series of interconnected LLM-invoking nodes, where each node represents an LLM action and the edges define the logic, dependencies, and flow between these actions. This structure transforms the workflow into a vast search space, encompassing a wide variety of potential configurations. Our goal is to efficiently navigate this space, automatically generating optimized workflows that maximize task performance while minimizing human intervention.
针对这些挑战,论文提出自动生成 agentic workflow 的框架。核心思想是把 workflow 建模为由 LLM 调用节点和边组成的结构:节点执行具体动作,边定义逻辑、依赖和数据流。这样,workflow 的设计就变成在巨大候选空间中寻找能最大化任务性能的结构。
However, the diversity and complexity of tasks present significant challenges. Specifically, each task can have different requirements, operations, and dependencies, which makes it difficult to represent them in a unified yet flexible manner~[cite: Chen2021Humaneval, cobbe2021gsm8k, zhi2018hot, DBLP:conf/icde/LuoQ0018]. Furthermore, the search space for possible workflows, comprising an immense number of code structures and node configurations, is virtually boundless, creating an additional challenge for efficient exploration and optimization.
任务的多样性和复杂性会让搜索变得困难。不同任务需要不同操作、依赖和约束,统一表示并不容易;同时,代码结构和节点配置形成的候选空间几乎没有边界,因此需要既灵活又高效的搜索机制。
To address these challenges, we propose AFlow, a Monte Carlo Tree Search (MCTS)-based framework designed to systematically explore and discover optimal agentic workflows. AFlow represents workflows as flexible nodes connected by code-based edges, which encapsulate possible relationships such as logical flows, conditions, and dependencies. These edges allow the workflow to be modeled as a graph~[cite: zhuge2024gptswarm] or network~[cite: liu2023dynamic], offering a powerful structure for capturing complex interactions between LLM invocations.
AFlow 用基于 MCTS 的框架系统探索 agentic workflow。它把 workflow 表示成由代码边连接的节点网络,从而表达逻辑流、条件和依赖关系;这种表示使搜索算法能够捕捉多次 LLM 调用之间的复杂交互,并逐步发现更优流程。
To enhance the search process and improve efficiency, AFlow introduces a novel concept of operators -- predefined, reusable combinations of nodes representing common agentic operations (e.g., Ensemble, Review & Revise). These operators serve as foundational building blocks for constructing workflows and are integrated into the search space, ensuring that the exploration process leverages known patterns of effective agentic operations.
为了提高搜索效率,AFlow 引入算子这一概念。算子是预定义、可复用的节点组合,代表常见 agentic 操作。算子既能把搜索空间限制在更可能有效的区域,也保留了通过代码边组合出新结构的灵活性。
AFlow employs the MCTS algorithm to navigate this infinite search space. The framework’s workflow optimization process incorporates several key innovations: a soft mixed-probability selection mechanism for node exploration, LLM-driven node expansion to introduce new possibilities, execution evaluation to assess workflow performance, and backpropagation of experience to refine future search iterations. This combination of techniques ensures that AFlow efficiently discovers workflows that adapt to the complexity of diverse tasks while reducing reliance on manual intervention.
AFlow 用 MCTS 遍历几乎无限的 workflow 空间。优化过程包含四个关键设计:软混合概率选择、基于 LLM 的扩展、执行评估以及经验回传。每一轮都会选择已有候选、生成修改、真实运行并把结果写回树结构。
We make the following key contributions: (1) Problem Formulation: We formalize the workflow optimization problem, generalizing prior approaches as specific cases. This provides a unified framework for future research at both the node and workflow optimization levels. (2) AFlow: We introduce AFlow, an MCTS-based method that automatically discovers effective workflows across multiple domains with minimal human intervention. (3) Extensive Evaluation: We evaluate AFlow on six benchmark datasets: HumanEval, MBPP, MATH, GSM8K, HotPotQA, and DROP. AFlow outperforms manually designed methods by 5.7% and surpasses existing automated approaches by 19.5%. Notably, workflows generated by AFlow enable smaller LLMs to outperform larger models, offering better cost-performance efficiency, with significant implications for real-world applications.
论文的贡献包括四点:提出 workflow 优化的形式化定义;给出 AFlow 这一结合代码表示、算子和 MCTS 的自动搜索框架;在问答、代码和数学六个基准上展示效果;并通过消融、成本分析和案例研究解释算子、树结构经验和执行反馈的作用。
In the flourishing landscape of Large Language Model (LLM) applications, autonomous agents ~[cite: zhuge2023mindstorms, hong2024data, jun2024mobile, wang2023voyager] and effective agentic workflows ~[cite: Tal2024Alpha, sirui2024meta] emerge as two distinct paradigms: the former emphasizing flexible autonomous decision-making, while the latter relies on predefined processes with multi-node LLM interactions, both demonstrating remarkable efficacy in their respective domains.
在 LLM 应用中,自主智能体和 agentic workflow 是两条常见路线。自主智能体强调动态决策和环境交互,而 workflow 更强调由步骤、工具和模型调用构成的可复用流程。AFlow 关注后者,希望把复杂任务中的人工流程设计自动化。
How can organizations ensure consistent execution of complex tasks?. When faced with complex yet common tasks, human societies often rely on well defined workflows ~ to ensure consistency and effectiveness across different individuals, rather than requiring each individual to plan and execute freely. This principle is equally applicable to LLMs. Existing works have focused on manually designing agentic workflows for LLMs to achieve effective performance on specific tasks ~, a process analogous to building agentic SOPs. Similar to the development of SOPs in human society, the process of building agentic SOPs requires leveraging domain knowledge for design, followed by extensive iterative refinement, which involves substantial labor costs.
组织如何保证复杂任务的一致执行,是论文背后的管理学类比。人类社会常用标准操作流程来处理重复但复杂的任务;类似地,agentic workflow 可以看作 LLM 系统中的操作流程,用于规定如何分解、调用、验证和整合。
The challenge of buliding agentic SOPs bears a striking resemblance to the early days of manually tuning machine learning model parameters. However, just as AutoML has emerged as a thriving field~[cite: alex2024automl, xin2021automl], the acquisition of agentic SOPs holds similar potential for automation. Recent research has explored various aspects of this domain, including prompt generation ~[cite: mert2024text, omar2024dspy, yong2024promst, xin2024promptagent, cheng2024opro], flow optimization ~[cite: hu2024automated, ze2024autoflow, zhuge2024gptswarm], and hyperparameter optimization ~[cite: saad2024archon], showing promise in reducing human desgin costs. Despite these advancements, the field lacks a comprehensive definition of the automated agentic SOP acquisition problem, which hinders subsequent researchers' understanding and progress in this area.
构建 agentic SOP 的困难类似早期机器学习中手调参数。AutoML 证明了许多设计可以自动搜索;AFlow 借鉴这一思想,把手工设计 workflow 的问题转成自动优化问题,从而降低新任务上的人工设计成本。
Inspired by this, we propose a complete structure for representing and process of automated acquiring agentic SOPs. From a top-down perspective, we define agentic SOPs as optimized workflows for LLMs, tailored to specific performance metrics associated with defined tasks. Each workflow can be decomposed into a control flow that manages data routing, incorporating several fundamental nodes for LLM invocation. By meticulously designing node parameters—including model, temperature~, output formats~ and prompt, we establish a foundational framework capable of representing a wide array of agentic workflows while providing interfaces for optimization. This structured approach transforms the problem of acquiring effective agentic workflows into a well-defined search problem. The algorithm for the automated acquisition of SOPs operates fundamentally as a search algorithm within this space, employing advanced methods such as heuristic search, monte carlo tree search (MCTS)~, bayesian optimization (BO)~, and hyperparameter tuning~.
受此启发,论文提出一套完整结构,用来表示并自动获取智能体标准操作流程。从自顶向下看,论文把这种流程定义为面向特定任务和性能指标优化过的语言模型工作流。每个工作流都可以拆成控制数据路由的控制流,并包含若干负责调用语言模型的基础节点。通过细致设计节点参数,包括模型、温度、输出格式和提示词,系统就能表示大量不同形态的智能体工作流,并为后续优化提供接口。这样,有效工作流的获取问题就被转化成定义清楚的搜索问题;自动获取流程的算法,本质上是在这个空间里运行启发式搜索、蒙特卡洛树搜索、贝叶斯优化或超参数调节等搜索方法。
相关工作
Related Work
相关工作
Agentic Workflow. Agentic workflow and autonomous agents ~[cite: zhuge2023mindstorms, hong2024data, jia2024mobile, wang2023voyager] represent two distinct paradigms of LLM application. The former completes tasks statically through predefined processes with multiple LLM invocations, while the latter solves problems dynamically through flexible autonomous decision-making. Compared to autonomous agents that require specific actions and decision patterns designed for the environment, agentic workflows can be constructed based on existing human domain experience and iterative refinement, offering higher potential for automated construction.
Agentic workflow 和自主智能体是两种相关但强调不同的范式。前者更重视预先组织好的流程、步骤和模型调用,后者更重视动态决策、环境交互和持续行动。AFlow 所处理的是如何自动生成和优化前一种 workflow。
Agentic workflows can be broadly categorized into general and domain-specific types. General workflows emphasize universal problem-solving approaches, such as ~[cite: wei2022COT, wang2022COTSC, madaan2023self, wang2023multipersona]. Domain-specific workflows focus on building effective processes to solve domain-specific problems, such as code generation ~[cite: sirui2024meta, Tal2024Alpha, li2024debug], data analysis ~[cite: yu2024hai, yi2024gen, bo2024nlsql, zhou2023llm], mathematics ~[cite: zhong2024achieving, xu2024lemur], question answering ~[cite: nori2023medprompt, zhou2024language]. Existing work has manually discovered numerous effective agentic workflows, but it's challenging to exhaust various tasks across different domains, further highlighting the importance of automated workflow generation and optimization.
Agentic workflow 大致可分为通用型和领域特定型。通用方法强调跨任务的解题策略,如思维链、自一致性、反思和多角色讨论;领域方法则针对代码、数学、问答或医疗等场景设计专门流程。
Automated Agentic Optimization. Recent work aims to automate the design of agentic workflows, categorized into three types: automated prompt optimization, hyperparameter optimization, and automated workflow optimization. Prompt optimization ~[cite: chirs2024probreed, mert2024text, cheng2024opro, omar2024dspy] uses LLMs to optimize prompts within fixed workflows. Hyperparameter optimization [cite: saad2024archon] focuses on optimizing predefined parameters. While these approaches improve performance, they are limited in generalization to new tasks and often require moderate human effort for task-specific designs.
自动化 agentic 优化可以分成提示词优化、超参数优化和 workflow 结构优化三类。提示词优化主要改变节点输入,超参数优化改变温度等运行参数,而 workflow 优化要调整节点连接、工具调用和控制流,因此空间更大也更难。
Automated workflow optimization~[cite: ze2024autoflow, wang2024symbo, zhuge2024gptswarm, hu2024automated] aims to optimize entire workflow structures, offering more potential for fully automated generation. Recent works explore diverse representations and methods. GPTSwarm~[cite: zhuge2024gptswarm] uses graph structures with reinforcement learning, but struggles to represent workflows with conditional states due to graph structure limitations. ADAS~[cite: hu2024automated] utilizes code structures to represent workflows and stores historical workflows in a linear list structure, aligning closely with our goals. However, it is constrained by the efficiency of its search algorithm as it relies on overly simplistic representations of experiences in the searching process, making it challenging to discover effective workflows.
自动 workflow 优化试图优化整个流程结构,相比只调提示词更有潜力,但也更容易遇到搜索空间巨大和反馈利用困难的问题。AFlow 通过代码表示、算子约束和 MCTS 经验回传来处理这些问题。
AFlow also uses code to represent workflows, but goes further by providing a more fundamental structure called named node. This structure encompasses various LLM invocation parameters, allowing for more detailed workflow representation. We also introduce operators that implement predefined node combination functions. Simultaneously, AFlow employs a specially designed MCTS algorithm for automated workflow optimization, leveraging the tree-structured experience and execution feedback to efficiently discover effective workflows.
AFlow 也使用代码表示 workflow,但进一步引入 named node 这类更基础结构,覆盖多种 LLM 调用形式,并把函数、算子、代码边和执行反馈纳入统一搜索框架。
预备知识
Preliminary
预备知识
In this section, we will first formulate the automated agentic workflows generation problem in Section~sub:problem and then discuss design considerations of our AFlow in Section~sub:design. For the core concept of this section, we provide an example explanation in Figure~formulation.
这一节先形式化自动生成 agentic workflow 的问题,再讨论 AFlow 的设计考虑。论文用图示解释节点、算子和边的关系,为后续把 workflow 转成可搜索代码结构做铺垫。
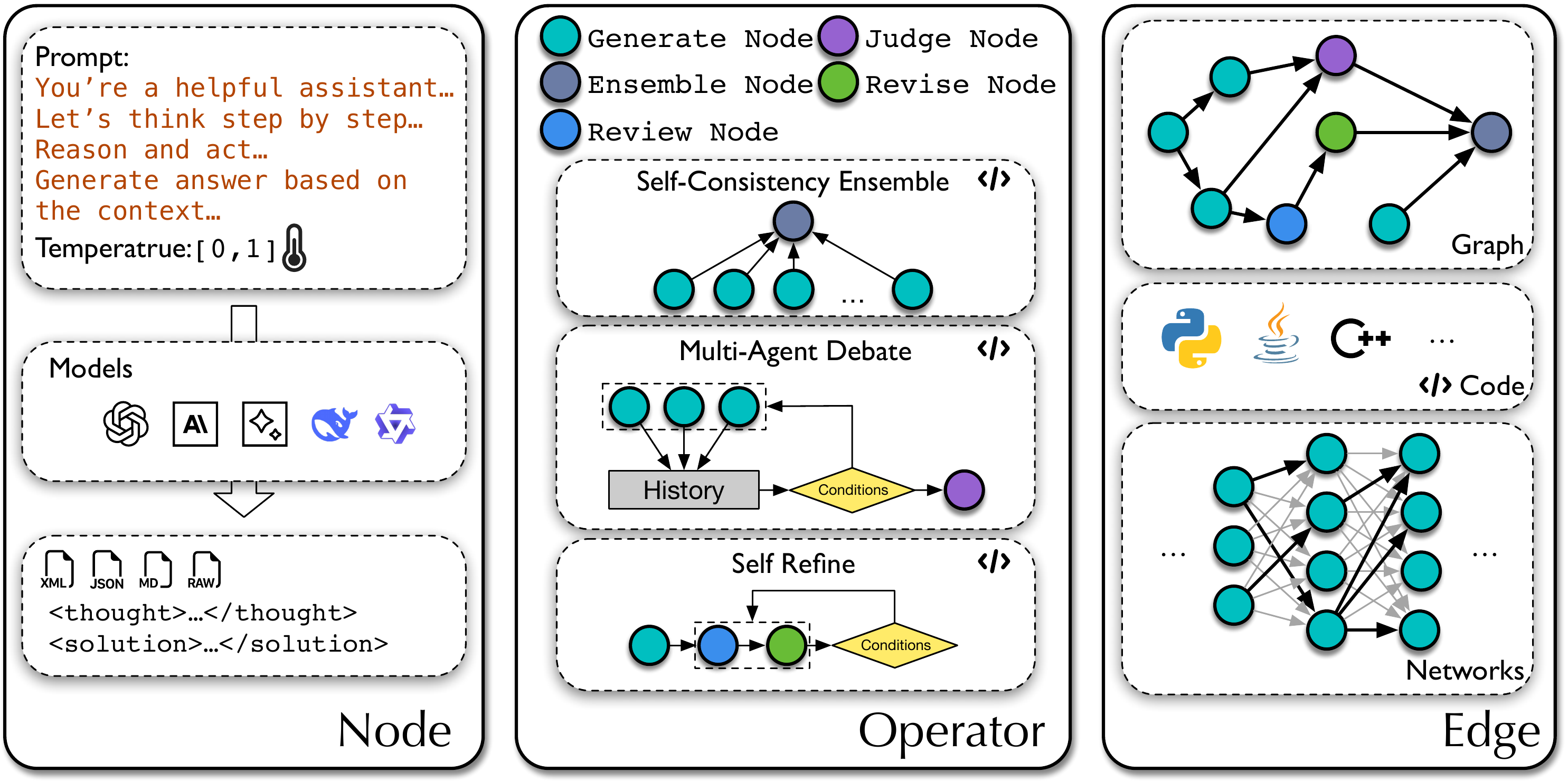
这张图解释论文的基本表示:节点可以携带模型、提示词、温度和输出格式等参数;算子把常见节点组合封装成可复用结构;边则表示执行顺序、条件分支、循环或代码控制流。它帮助读者理解 AFlow 为什么把 workflow 看成可执行、可搜索的程序。
问题形式化
Problem Formulation
问题形式化
Agentic Workflow. We define an agentic workflow W as a series of LLM-invoking nodes connected by edges to define the exection orders, denoted as . Each node represents a specific operation performed by an LLM and is characterized by the following parameters. The code abstraction of the node is shown in Appendix appendix:node structure. • Model : The specific language model invoked at node . • Prompt : The input or task description provided to the model at each node. • Temperature $N_iF$: The format in which the model's output is structured (e.g., xml, json, markdown, raw). The node in workflow should provide different output formats, inspired by the ~zhi2024format.
论文把 agentic workflow 定义为一系列通过边连接的 LLM 调用节点,节点集合记为 。每个节点代表一次由 LLM 执行的特定操作,并由模型、提示词、温度和输出格式等参数刻画;附录进一步给出代码抽象。
Edge represent abstract structures defining node relationships, governing the sequence of execution. The edge can be represented via various structures, such as:
边 表示节点关系和执行顺序,可以用图、神经网络或代码等结构表达。图适合层级、串行、并行和分支关系;神经网络可以表达自适应转移;代码则能表达线性序列、条件逻辑、循环以及图或网络结构,因而提供最精确的控制。
• Graph ~[cite: zhuge2024gptswarm]: A flexible structure representing hierarchical, sequential, or parallel relationships between nodes, allowing for complex branching workflows. • Neural Network ~[cite: liu2023dynamic]: A structure that can represent complex, non-linear relationships between nodes, allowing for adaptive and learnable workflows based on input and feedback. • Code ~[cite: hu2024automated]: A comprehensive representation that can express linear sequences, conditional logic, loops, and incorporate graph or network structures, offering the most precise control over workflow execution for LLMs.
图结构虽然能表示 workflow 关系,但基础 DAG 不容易自然表达并行和条件逻辑,往往需要 Petri net 或 BPMN 等扩展;神经网络能自适应转移,却缺少精确执行控制。代码天然支持这些关系,因此论文选择代码作为主要边结构以最大化表达能力。
While graph structures can represent workflow relationships, they require complex extensions (e.g., Petri nets, BPMN) beyond basic DAGs to naturally express parallel execution and conditional logic. Neural networks enable adaptive transitions but lack precise control over workflow execution. In contrast, code representation inherently supports all these relationships through standard programming constructs. Therefore, we adopt code as our primary edge structure to maximize expressivity.
图结构虽然能表达工作流关系,但基础有向无环图并不天然支持并行执行和条件逻辑,往往需要更复杂的流程建模扩展。神经网络结构可以根据输入和反馈产生自适应转移,但缺少对执行顺序和变量传递的精确控制。相比之下,代码表示可以直接使用条件判断、循环、函数调用和复杂数据结构,因此更适合作为 AFlow 的主要边结构,并最大化工作流表达能力。
Automated Workflow Optimization. Given a task and an evaluation function , the goal of workflow optimization is to discover a workflow that maximizes . This can be formulated as a search process where an algorithm explores the search space $$ for a workflow optimization problem encompasses all possible configurations of node parameters and edge structures:
workflow 优化的搜索空间包含所有可能的节点参数和边结构配置。节点参数包括可选语言模型、温度、提示词和输出格式,边结构集合则描述 workflow 中可能的执行关系。
where , with representing the sets of possible language models, prompts, output formats, and edge configurations, respectively.
这里进一步说明搜索空间中的变量含义:模型集合给出可调用语言模型的范围,提示词集合给出节点输入的可能写法,输出格式集合规定结果结构,边配置集合描述节点之间可能的执行关系。工作流搜索就是在这些模型、提示词、格式和边结构的组合中,寻找能够稳定完成任务的有效配置。
With this formulation, the workflow optimization problem can be expressed as:
有了上述形式化,workflow 优化可以写成两个目标:搜索算法 从 、 和 中产生候选 workflow;最终目标 是在搜索空间中让评估函数得分最高的配置。
where is the search algorithm that explores the search space $W^*GT$.
其中 是探索搜索空间的算法, 是给定任务和评估函数下的最优 workflow。这个表达把人工设计流程的问题转成可优化、可比较的搜索问题。
AFlow 概览
AFlow Overview
AFlow 概览
Limitations of Previous Methods. Previous approaches ~[cite: mert2024text, omar2024dspy, zhuge2024gptswarm] to workflow optimization have primarily been constrained by the limited scope of their search spaces, based on problem definition in Section~sub:problem. Another related work, ADAS~[cite: hu2024automated], searches in a larger space comprising a combination of prompts and edges , but fails to discover effective workflows due to the efficiency limitations of its linear heuristic search algorithm.
过去的 workflow 优化方法主要受限于搜索空间范围。ADAS 搜索提示词和边的组合,空间更大,但线性启发式搜索效率不足,难以发现真正有效的 workflow。AFlow 的动机正是扩大表达能力的同时改善搜索效率。
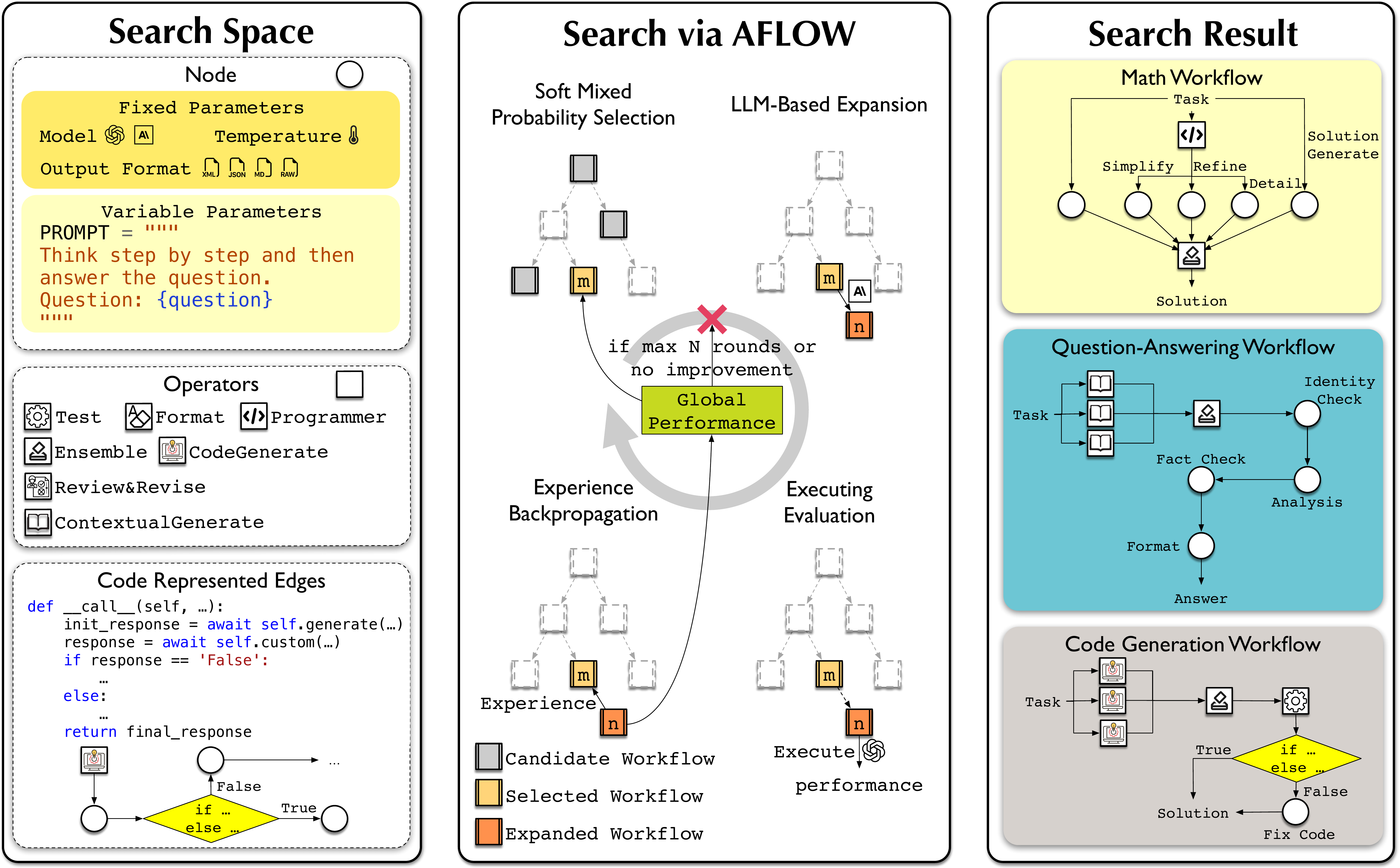
这张图展示 AFlow 的整体框架。搜索空间由提示词可变的节点、给定算子集合和代码表示的边组成;AFlow 在这个空间中执行 MCTS 式循环,包括软混合概率选择、基于 LLM 的扩展、执行评估和经验回传,直到达到最大迭代轮数或收敛条件。
Formulation. To address the limitations of previous methods, we propose AFlow, a novel framework that leverages Large Language Models (LLMs) as optimizers within a variant of Monte Carlo Tree Search (MCTS) to search for optimal workflows. As discussed in Section para:workflow, edges can be represented in both graphs and code. To ensure AFLOW can explore the full range of possible agentic workflows, we represent nodes N and edges E through code. Specifically, as shown in Figure~mcts, AFlow uses a variant of MCTS to iteratively explore the workflow search space, evaluate different configurations, and backpropagate experiences to refine the workflow optimization process.
为克服此前方法搜索空间过窄或搜索效率不足的问题,论文提出 AFlow:它把大语言模型放入一种蒙特卡洛树搜索变体中,作为生成新工作流的优化器。AFlow 用代码表示节点和边,以覆盖更完整的智能体工作流空间;每次迭代都会探索候选配置、执行评估,并把经验回传到搜索树中,用于后续优化。
To enhance search efficiency in practice, we simplify the search space by fixing key parameters such as the model , temperature $FENE$ into unified interfaces, thereby enabling more efficient utilization by AFlow. By employing these Operators, we achieve more efficient search and streamlined workflow generation.
为了在实践中提高搜索效率,AFlow 固定模型、温度和输出格式等关键参数,把搜索重点放在代码表示的边和提示词上。同时引入 Operators,把 Ensemble、Review、Revise 等常见 agent 操作封装成统一接口,从而让搜索更集中、更高效。
Formally, given a set of Operators $$ represented through code, the optimization problem can be formalized as:
形式上,AFlow 的搜索空间由提示词 、代码边 和算子 组成。提示词来自提示词集合,边来自代码边空间,算子来自预定义算子集合;这些元素共同定义可执行 workflow。
该公式定义 AFlow 的简化搜索空间:候选 workflow 由多个提示词、代码表示的边以及算子组合构成。它说明 AFlow 并不搜索所有模型、温度和格式参数,而是把重点放在更影响流程结构的提示词、边和算子上。
该公式定义 AFlow 的简化搜索空间:候选 workflow 由多个提示词、代码表示的边以及算子组合构成。它说明 AFlow 并不搜索所有模型、温度和格式参数,而是把重点放在更影响流程结构的提示词、边和算子上。
Tasks Scope and Operations.
论文关注带有数值评估函数的推理任务,并从已有工作中抽取常见操作作为算子集合,包括生成、格式化、审阅与修订、集成、测试、程序员算子,以及用于基础节点构造的自定义算子。这个算子集合可以继续扩展,以便提升不同任务上的搜索效率。即使没有任何预定义算子,AFlow 也能用基础自定义算子构造不同工作流节点;带算子和不带算子的效率差异会在消融实验中比较,附录还给出各个算子的详细代码结构。
In this paper, we focus on applying AFlow to reasoning tasks with numerical evaluation functions. We extract common operations from existing literature and define them as part of the operator set~$$ can be easily expanded to enhance search efficiency for various tasks. Even without any predefined operators, AFlow can construct different workflow nodes using the basic Custom operator. The efficiency comparison between these approaches is detailed in Section~sec:ablation. For a comprehensive understanding of the operators, we provide their detailed structures in Appendix~appendix:operator_code.
论文关注带有数值评估函数的推理任务,并从已有工作中抽取常见操作作为算子集合,包括生成、格式化、审阅与修订、集成、测试、程序员算子,以及用于基础节点构造的自定义算子。这个算子集合可以继续扩展,以便提升不同任务上的搜索效率。即使没有任何预定义算子,AFlow 也能用基础自定义算子构造不同工作流节点;带算子和不带算子的效率差异会在消融实验中比较,附录还给出各个算子的详细代码结构。
AFlow 设计细节
The Design Details of AFlow
AFlow 设计细节
The core concept of AFlow is to employ Large Language Models (LLMs) as optimizers within a Monte Carlo Tree Search (MCTS) variant to discover effective workflows. In our MCTS structure, each tree node represents a complete workflow rather than individual LLM-invoking node, enabling the discovery of universal solutions for classes of problems. The search process operates through an iterative cycle of soft mixed probability selection, LLM-based optimization expansion, execution evaluation, and experience backpropagation until reaching maximum iterations or convergence criteria. A simplified illustration is shown in Figure mcts, with detailed algorithm process and theoretical analysis presented in Appendix appendix:algorithmaflow and Appendix appendix:theroy, respectively.
AFlow 的核心是在 MCTS 变体中使用 LLM 作为优化器来发现有效 workflow。与把树节点看成单个 LLM 调用不同,AFlow 的每个树节点代表一个完整 workflow,因此搜索对象是可复用的完整解决方案。搜索循环包括软混合概率选择、基于 LLM 的优化扩展、执行评估和经验回传。
Existing workflow optimization methods iteratively use past workflow structures to prompt LLMs to discover new structures. However, due to information loss during accumulation (as input tokens increase), this approach struggles to guide LLMs towards specific performance metrics. Combined with the vast search space of code, this reduces search efficiency. Our key idea is to leverage the tree structure of MCTS to preserve workflow-based exploration experiences in rounds workflow optimization. When a workflow is revisited, we accurately reuse past successful experiences and avoid failures, enabling effective workflow generation and improving search efficiency. To prevent local optima, we introduce a special selection mechanism allowing generation from a blank template at any round. Next, we will introduce the complete process of AFlow, as shown in Algorithm alg:concise-mcts-workflow-optimization.
现有方法常把过去 workflow 线性塞进提示词,让 LLM 继续发现新结构。但随着输入变长,历史信息会丢失,模型难以知道哪些修改真正改善了指标;再加上代码搜索空间巨大,搜索效率会降低。AFlow 的关键想法是用 MCTS 树结构保存每轮 workflow 优化经验。
1Require: Evaluator , Dataset , Operators 2Ensure: Optimized Workflow 3Initialize , split into and 45for to :6 Select(tree)7 Expand(, )8 Evaluate(, , )9 Backpropagate(, )10 Update if improved11 if ConvergenceCriteriaMet():12 break13return 该算法概括 AFlow 的主循环。输入是评估器、数据集和算子集合,输出是优化后的 workflow。流程先初始化模板 workflow 并划分验证集和测试集,然后在每轮迭代中从搜索树选择一个 workflow,调用 LLM 基于算子与历史经验扩展出子 workflow,在验证集上多次执行评估,把分数和修改经验回传到搜索树,并在性能提升时更新当前最优 workflow;若满足收敛条件则提前结束。
Initialization AFlow begins with a template workflow , which provides a framework for invoking nodes and operators. The code template, detailed in Appendix appendix:graph structure, allows the LLM optimizer to complete workflow simply by completing call functions. Prior to initiating the search process, we randomly partition the dataset into a validation set (20%) and a test set (80%), with the random seed fixed at 42. To optimize computational efficiency, AFlow then executes the blank template five times on the validation dataset. From these executions, we select a subset of problems that exhibit high variance in scores, which becomes the final validation set.
初始化阶段,AFlow 从模板 workflow 开始。模板提供调用节点和算子的框架,优化器只需补全调用函数。搜索前,数据集随机划分为 20% 验证集和 80% 测试集,随机种子固定为 42;随后空模板在验证集上执行五次,选择分数方差较高的问题作为最终验证集。
Selection Our algorithm forms the initial workflow by evaluating an empty workflow on the validation set. And then continuously select workflows based on a soft mixed probability selection strategy. c We propose this strategy for workflow optimization: combining uniform and score-based weighted probability distributions to select from top-k workflows and the initial workflow, where including the initial workflow ensures persistent exploration capability while avoiding local optima. The formula for this selection strategy is as follows:
选择阶段先评估空 workflow 形成初始节点,然后持续使用软混合概率策略选择 workflow。该策略把均匀分布和基于分数的加权分布结合起来,在 top-k workflow 和初始 workflow 之间采样;保留初始 workflow 可维持探索能力,避免过早陷入局部最优。
该公式给出软混合概率选择策略:一部分概率来自均匀探索,一部分概率来自按得分加权的利用项。这样既能偏向高分 workflow,又能保留探索低分或初始模板的机会。
公式中的 表示候选工作流数量, 表示第 个工作流的分数, 表示当前最高分。参数 控制分数差异对采样概率的影响,参数 控制均匀探索与分数利用之间的比例。这个选择策略让高分工作流更容易被扩展,同时仍保留探索其他路径的机会。
Expansion In the expansion phase, we employ an LLM as an optimizer to create new workflows and the optimize prompt is illustrated in Appendix appendix:prompt. The optimizer leverages the selected workflow's experience to generate new prompts or modify node connections by altering code, resulting in new workflows. Specifically, to maximally uncover insights from past iterations, the experience includes all modifications and their corresponding improvements or failures on the selected workflow, along with precise logs of predictions and expected output.
扩展阶段使用 LLM 作为优化器创建新 workflow,具体优化提示词在附录中给出。优化器会读取被选中 workflow 的经验,生成新提示词或通过修改代码改变节点连接;经验包含该路径上的修改、提升或失败记录,以及预测日志和期望输出。
Evaluation AFlow directly executes workflows to get feedback due to explicit evaluation functions in reasoning tasks. We test each generated workflow 5 times on the validation set, computing mean and standard deviation. While this increases per-iteration cost, it provides more accurate feedback for the optimizer. This precision enhances search efficiency, ultimately reducing the number of iterations required to reach an effective solution.
评估阶段,由于推理任务具有明确评估函数,AFlow 直接执行候选 workflow 获取反馈。每个新 workflow 在验证集上测试五次,计算均值和标准差。虽然单轮成本更高,但反馈更准确,能减少达到有效方案所需的迭代次数。
Backpropagation After execution, we record: (1) the workflow's performance, (2) the optimizer's modification of its parent workflow, and (3) optimization success relative to its parent. This information is stored in experience and propagated back to the parent workflow, while the performance score is added to the global record for selection.
回传阶段记录三类信息:workflow 的性能、优化器相对父 workflow 做了什么修改、以及相对父节点是否优化成功。这些信息会存入经验并回传给父 workflow,性能分数也加入全局记录供后续选择使用。
Terminal Condition We implement early stopping to reduce unnecessary execution costs: the process terminates if the top-k average score shows no improvement for consecutive rounds, or after total rounds otherwise. See Appendix appendix:algorithmaflow for algorithmic details.
终止条件用于减少不必要的执行成本。如果 top-k workflow 的平均分连续若干轮没有提升,或者达到总轮数上限,搜索就停止。附录给出更完整的算法细节。
实验
Experiments
实验
实验设置
Experimental Setup
实验设置
Datasets We utilized six public benchmarks for our experiments. Following established practices~[cite: saad2024archon, hu2024automated] in workflow optimization, we divide the data into validation and test sets using a 1:4 ratio. Specifically, we use the full datasets for GSM8K~[cite: cobbe2021gsm8k], HumanEval~[cite: Chen2021Humaneval], and MBPP~[cite: austin2021mbpp]. For HotpotQA ~[cite: zhi2018hot] and DROP ~[cite: dheer2019drop], we randomly select 1,000 samples each, in line with~[cite: hu2024automated, Noah2023reflexion]. For the MATH~[cite: hendrycks2measuring] dataset, we follow~[cite: hong2024data] in selecting 617 problems from four typical problem types (Combinatorics & Probability, Number Theory, Pre-algebra, Pre-calculus) at difficulty level 5.
实验使用六个公开基准,并按照既有工作流优化实践把数据按一比四划分为验证集和测试集。小学数学、代码生成两个数据集使用完整数据;两个问答数据集各随机选取一千个样本;竞赛数学数据集则选取组合概率、数论、预代数和预微积分四类难度五题目,共六百一十七道。这样的设置覆盖问答、代码和数学推理三类任务。
Baselines We compare workflow discovered by AFlow against manually designed methods for LLMs, including IO (direct LLM invocation), Chain-of-Thought ~[cite: wei2022COT], Self Consistency CoT (5 answers) ~[cite: wang2022COTSC], MultiPersona Debate ~[cite: wang2023multipersona], Self-Refine (max 3 iteration rounds)~[cite: madaan2023self], and MedPrompt (3 answers and 5 votes) ~[cite: nori2023medprompt]. We also compared against workflow designed by automated workflow optimization method ADAS~[cite: hu2024automated].
基线包括多种手工设计的语言模型工作流:直接调用模型、思维链、生成五个答案后做自一致性选择、多角色讨论、最多三轮自我修订,以及使用三份答案和五次投票的医疗提示流程。论文还加入自动工作流优化方法 ADAS 作为对比,用来区分 AFlow 相对其他自动设计流程方法的收益。
Implementation Details AFlow utilizes different models for optimization and execution. We employ Claude-3.5-sonnet ~[cite: sonnet2024anthropic] as the optimizer and use models: DeepSeek-V2.5~[cite: deepseekv252024Deepseek], GPT-4o-mini-0718~[cite: gpt4omini2024openai], Claude-3.5-sonnet-0620~[cite: sonnet2024anthropic], GPT-4o-0513~[cite: gpt4o2024openai]) as executors. All models are accessed via APIs. We set the temperature to 1 for DeepSeek-V2.5 and to 0 for the other models. We set iteration rounds to 20 for AFlow. For ADAS, we use Claude-3.5-sonnet as the optimizer and GPT-4o-mini as the executor, with the iteration rounds set to 30.
实现上,AFlow 区分优化模型和执行模型。优化器使用一个能力较强的 Claude 系列模型,执行模型则包括 DeepSeek、小型 GPT、Claude 和 GPT-4o 等不同能力与价格的模型。除 DeepSeek 的温度设为一以外,其他执行模型温度设为零。AFlow 搜索二十轮;对照的自动设计方法使用同一优化模型和小型 GPT 执行,并搜索三十轮。
Metrics. For GSM8K and MATH, we report the Solve Rate (%) as the primary metric. For HumanEval and MBPP, we report the pass@1 metric as presented in~[cite: Chen2021Humaneval] to assess code accuracy. For HotpotQA and DROP, we report the F1 Score. Additionally, for all datasets, we calculate the cost by tracking token usage to construct a pareto front, visually demonstrating the performance-cost trade-offs between different methods.
指标按任务类型设置:两个数学数据集使用求解成功率,两个代码数据集使用一次生成通过率,两个问答数据集使用 F1 分数。论文还统计每种方法的调用成本,也就是由令牌使用量换算出的费用,并据此绘制性能与成本之间的帕累托前沿,用来比较不同流程的性价比。
实验结果与分析
Experimental Results and Analysis
实验结果与分析
Results The main experimental results, as shown in Table tab:main result, demonstrate the effectiveness of AFlow. Workflows optimized by AFlow outperform all manually designed methods by an average of 5.7% and surpass contemporary automatic workflow optimization work by 19.5%. Across six datasets in QA, Code, and Math domains, AFlow achieves an average performance of 80.3%, marking the capability and usability of this method. Notably, compared to similar works, AFlow performed better on more challenging tasks, improving over ADAS on MATH and MBPP tasks by 57%, showcasing the robustness of the model on complex datasets.
主实验结果表明 AFlow 有效。AFlow 优化出的 workflow 平均比所有手工设计方法高 5.7%,比同期自动 workflow 优化方法高 19.5%。在问答、代码和数学六个数据集上,AFlow 平均表现达到 80.3%;在更难的 MATH 和 MBPP 上,它相对 ADAS 的提升达到 57%,显示出对复杂任务的鲁棒性。
Comparison of performance between manually designed methods and workflow generated by automated workflow optimization methods in QA, code, and Math scenarios. All methods are executed with GPT-4o-mini on divided test set, and we tested it three times and reported it on the average.
表格比较在小型执行模型下,手工设计方法和自动工作流优化方法在问答、代码和数学六个基准上的平均表现。AFlow 的平均分为 80.3,高于直接调用、思维链、自一致性、医疗提示、多角色讨论、自我修订和 ADAS 等对照方法。分任务看,AFlow 在两个问答集、两个代码集和两个数学集上都取得最高或最优平均结果,说明收益并不局限于单一任务类型。
Comparison of performance between manually designed methods and workflows generated by AFlow with two executor LLM: GPT-4o-mini ("Ours") and DeepSeek-V2.5 ("Ours*"). All workflows are tested thrice on the humaneval test set, with average results reported. "MP" denotes "MedPrompt"~[cite: nori2023medprompt], and "MPD" denotes "MultiPersona Debate"~[cite: wang2023multipersona]. The results demonstrate that workflows obtained through AFlow exhibit strong transferability.表格检验 AFlow 搜索出的工作流是否能迁移到不同执行模型。四类执行模型上,AFlow 发现的流程大多超过对应直接调用、思维链、自一致性、医疗提示、多角色讨论和自我修订基线。与此同时,不同模型的最优流程并不完全相同,说明模型能力和流程结构之间存在匹配关系,不能假设一个流程对所有模型都最优。
To explore whether the workflow searched by AFlow is model-agnostic, we use GPT-4o-mini and DeepSeek-V2.5 as execution LLMs to search effective workflows with different structures, with the results illustrated in Table tab:humaneval. When applying these workflows to other models, the vast majority demonstrate stronger performance than the baseline, showcasing the generalizability of the workflows discovered by AFlow. Simultaneously, we observe that the workflow identified using DeepSeek-V2.5 performs notably weaker on GPT-4o-mini compared to the workflow found using GPT-4o-mini itself. This suggests that different language models require different workflows to achieve their optimal performance.
为了检验搜索出的工作流是否与模型无关,论文分别用两种执行模型搜索不同结构的有效流程,再把这些流程迁移到其他模型上测试。结果显示,多数迁移流程强于基线,说明 AFlow 搜索出的结构具有一定泛化能力;但某些由一个模型搜索出的流程迁移到另一个模型时表现较弱,表明不同语言模型仍需要与自身能力匹配的流程才能达到最佳效果。
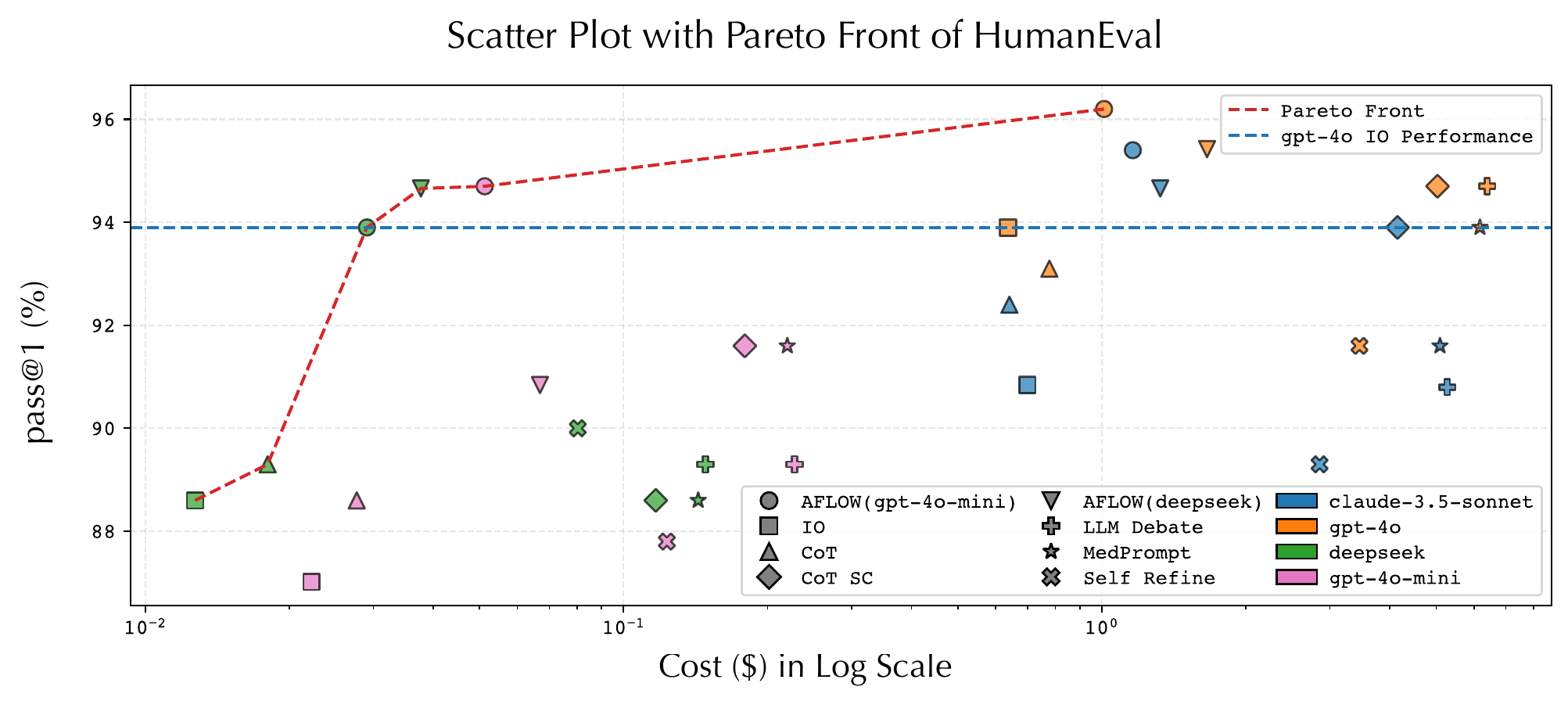
这张图展示 HumanEval 测试集上的成本与性能权衡。成本指执行划分后测试集的总花费,颜色表示测试阶段使用的执行模型。图的重点是 AFlow 能找到让较弱或更便宜模型接近甚至超过强模型直接调用的 workflow。
Analysis We demonstrate the comparison of performance and cost between the baselines and the top three workflows found by AFlow using GPT-4o-mini and DeepSeek-V2.5 as execution LLMs. The comparison is made across four models with different capabilities and price points. Results demonstrate that AFlow can identify workflows that allow weaker models to outperform stronger models on the pareto front of cost-effectiveness. This breakthrough effectively removes barriers to the widespread application of agentic workflows across various domains. By automating the design of effective agentic workflows, AFlow eliminates the human labor costs previously required. Moreover, the ability to achieve superior performance at lower costs compared to stronger models opens up further possibilities for widespread adoption.
成本分析比较了基线和 AFlow 找到的前三个 workflow 在不同执行模型上的性能与成本。结果显示,AFlow 可以找到让较弱模型在成本-效果帕累托前沿上超过较强模型的 workflow。自动化设计有效流程不仅减少人工设计成本,也让低成本模型有机会承担复杂任务。
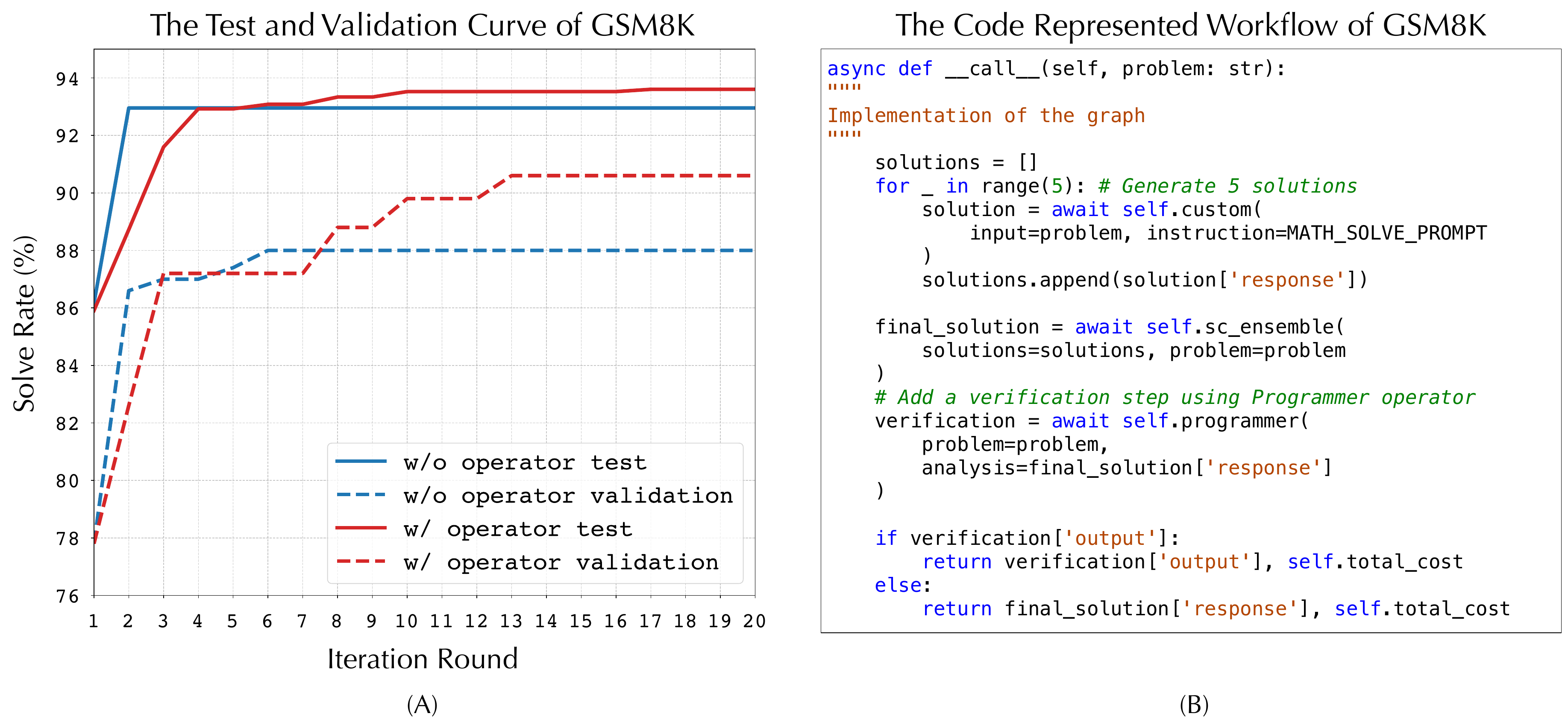
这张图包含两部分:左侧比较 GSM8K 上带算子和不带算子的 AFlow 在验证集与测试集上的最高性能曲线,右侧展示不带预定义算子时自动发现的最佳 workflow 代码。它说明算子能提升搜索效率,但 AFlow 即使没有算子也能形成类似 ensemble 的有效结构。
We introduce operators as human-designed effort to enhance search efficiency. An ablation study on GSM8K (Figure~fig:ablation) shows that operators help AFlow discover better workflows more efficiently, achieving incremental improvements. Notably, even without operators, AFlow maintains strong performance (93.1%), surpassing manual designs. Notably, AFlow autonomously develops ensemble-like structures without operators, demonstrating its capability for independent workflow design and marking a significant step towards full automation. Details is shown in Appendix appendix:case_study.
消融研究把算子视为一种人类设计努力,用来提高搜索效率。GSM8K 上的结果显示,带算子的 AFlow 能更高效发现更好 workflow,并呈现多次小幅提升;即使没有算子,AFlow 仍达到 93.1% 的强表现,超过手工设计方法,并自发发展出类似 ensemble 的结构。
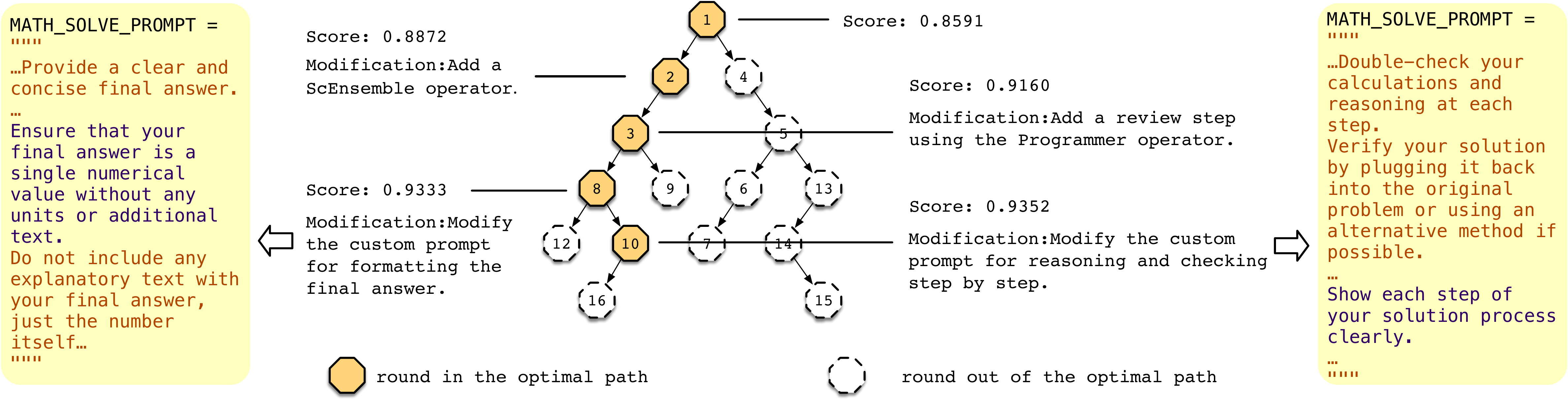
这张图展示 AFlow 在 GSM8K 上的树结构迭代过程。图中从第 1 轮初始节点追踪到最佳 workflow,标出每个节点分数以及相对父节点的修改;两侧紫色区域突出提示词的关键变化,用来说明树结构经验如何指导后续搜索。
Study AFlow demonstrates a clear iteration process, as shown in Figure fig:casestudy, illustrating how it evolves from a blank template (containing only a single Node without prompts) to the structure presented in Figure fig:ablation(B). In each iteration, AFlow employs a single-step modification, meaning it either adds one operator (rounds 2, 3) or makes a targeted modification to a prompt (rounds 8, 10). Among the unsuccessful exploration rounds, AFlow introduced a custom review node that directly modified answers generated through complex processes without additional reasoning (round 5), which decreased accuracy. In round 14, AFlow attempted to rephrase the problem but overly focused on "discount" information, leading to a decrease in accuracy. This iteration process showcases how tree-based search allows AFlow to further optimize known paths while retaining the ability to explore new ones. On the MBPP dataset, AFlow discovered structures similar to current manually designed workflows, such as test generation and execution by LLMs as seen in Tal2024Alpha. The workflow and more discovered results are presented in Appendix appendix:case_study and a complete optimization process is presented in Appendix sec:trajectory.
案例研究展示 AFlow 如何从空模板逐步演化到最佳 workflow。每次迭代通常只做单步修改,例如添加一个算子或调整提示词;失败分支也有解释,例如某轮加入自定义 review 节点反而降低准确率,另一次过度关注折扣信息导致退化。树搜索使 AFlow 能继续优化已知好路径,同时保留探索新路径的能力。
结论
Conclusion
结论
This paper has introduced AFlow, a novel framework for automated workflow optimization. We have comprehensively formulated the automated workflow optimization problem, establishing a foundational structure for future research. AFlow has leveraged Monte Carlo Tree Search and code-represented workflows to navigate the vast search space of possible workflows efficiently. Our experiments across six benchmarks demonstrate the effectiveness of AFlow, which has outperformed manually designed methods and existing automated optimization approaches. Ablation studies have shown that AFlow can autonomously discover effective structures, even without predefined operators. Importantly, AFlow has enabled weaker models to outperform stronger ones on the Pareto front of cost-effectiveness. We further discuss the potential applications of AFlow across diverse domains in Appendix appendix:discussion, potentially revolutionizing the adoption of agentic workflows across various domains. These results have highlighted AFlow's potential for enhancing LLMs' problem-solving capabilities while optimizing computational costs.
论文提出 AFlow,这是一个用于自动 workflow 优化的新框架。它系统形式化了自动 workflow 优化问题,并用结合代码表示、算子和 MCTS 的方法自动发现高性能流程。实验表明,AFlow 能在多个复杂任务上提升性能,同时降低人工设计成本,为更广泛部署 agentic workflow 提供了可行路径。
Acknowledgements
Acknowledgements
致谢:本研究得到中国国家自然科学基金、广州市大数据智能重点实验室、广东省基础与应用基础研究基金、广州市基础与应用基础研究基金以及广州-香港科技大学(广州)联合资助项目支持。
This paper is supported by NSF of China (62402409), Guangzhou Municipality Big Data Intelligence Key Lab (2023A03J0012), Guangdong Basic and Applied Basic Research Foundation (2023A1515110545), Guangzhou Basic and Applied Basic Research Foundation (2025A04J3935), and Guangzhou-HKUST(GZ) Joint Funding Program (2025A03J3714).
致谢:本研究得到中国国家自然科学基金、广州市大数据智能重点实验室、广东省基础与应用基础研究基金、广州市基础与应用基础研究基金以及广州-香港科技大学(广州)联合资助项目支持。
附录
Appendix
附录
LLM Based Expansion: Prompt for LLM Optimizer
LLM Based Expansion: Prompt for LLM Optimizer
基于 LLM 的扩展:LLM 优化器提示词
[title= Workflow optimize prompt, boxrule=2pt, arc=0mm, breakable]
这里是附录中的工作流优化提示词代码框。读者需要关注的不是排版参数,而是随后的提示词如何约束优化器:它要求只做一次明确修改,输出完整可运行的图结构和提示词,并避免生成无用或含空缺标记的提示。
1PROMPT = """You are building a Graph and corresponding Prompt to jointly solve {type} problems. Referring to the given graph and prompt, which forms a basic example of a {type} solution approach, please reconstruct and optimize them. You can add, modify, or delete nodes, parameters, or prompts. Include your single modification in XML tags in your reply. Ensure they are complete and correct to avoid runtime failures. When optimizing, you can incorporate critical thinking methods like review, revise, ensemble (generating multiple answers through different/similar prompts, then voting/integrating/checking the majority to obtain a final answer), selfAsk, etc. Consider Python's loops (for, while, list comprehensions), conditional statements (if-elif-else, ternary operators), or machine learning techniques (e.g., linear regression, decision trees, neural networks, clustering). The graph complexity should not exceed 10. Use logical and control flow (IF-ELSE, loops) for a more enhanced graphical representation.Ensure that all the prompts required by the current graph from prompt_custom are included.Exclude any other prompts. Output the modified graph and all the necessary Prompts in prompt_custom (if needed).The prompt you need to generate is only the one used in `prompt_custom.XXX` within Custom. Other methods already have built-in prompts and are prohibited from being generated. Only generate those needed for use in `prompt_custom`; please remove any unused prompts in prompt_custom. the generated prompt must not contain any placeholders. Considering information loss, complex graphs may yield better results, but insufficient information transmission can omit the solution. It's crucial to include necessary context during the process."""这段提示词规定 LLM 优化器如何重构图结构和提示词。它要求优化器只能做一次明确修改,可增加、删除或调整节点、参数、提示词和代码边,并用 XML 标签返回完整可运行的结果;同时鼓励使用 review、revise、ensemble、自问自答、条件分支和循环等结构,但限制图复杂度不超过 10,避免运行失败和信息传递丢失。
Basic Structure of Node
Basic Structure of Node
节点的基本结构
[title= Node structure, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
这里是附录中的节点结构代码框。随后的代码展示基础节点如何接收上下文、语言模型和输出格式,并把一次模型调用封装成可被工作流组合、执行和评估的对象。
1class ActionNode:2 async def fill(self, context, llm, schema...):3 """4 :param context: Everything we should know when filling node.5 :param llm: Large Language Model with pre-defined system message.6 :param schema: json/markdown/xml, determine example and output format.7 - raw: free form text8 - json: it's easy to open source LLM with json format9 - markdown: when generating code, markdown is always better10 - xml: its structured format is advantageous for constraining LLM outputs11 """12 ...13 return self这段代码给出 AFlow 节点抽象。`ActionNode.fill` 接收上下文、LLM 和输出 schema,负责把一次模型调用封装成可控节点;schema 可以是 raw、json、markdown 或 xml,不同格式对应不同的约束能力。
Basic Structure of Workflow
Basic Structure of Workflow
工作流的基本结构
[title= Workflow structure, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
这里是附录中的工作流结构代码框。随后的代码展示候选流程如何保存任务类型、模型配置和成本管理器,并要求子类实现实际调用逻辑,因此每个被搜索的流程都可以作为程序运行。
1DatasetType = Literal["HumanEval", "MBPP", "GSM8K", "MATH", "HotpotQa", "DROP"]2 3class Workflow:4 def __init__(5 self,6 name: str,7 llm_config,8 dataset: DatasetType,9 ) -> None:10 self.name = name11 self.dataset = dataset12 self.llm = create_llm_instance(llm_config)13 self.llm.cost_manager = CostManager()14 15 async def __call__(self, problem: str):16 """17 Implementation of the workflow18 """19 raise NotImplementedError("This method should be implemented by the subclass")这段代码定义 workflow 的基本类。它记录任务数据集、LLM 实例和成本管理器,并要求子类实现 `__call__`;因此 AFlow 搜索到的候选 workflow 本质上都是可执行的 Python 调用结构。
Operators
Operators
算子
[title= Operators, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
这里是附录中的材料标题或代码框配置,对应 Operators 的实现示例;真正需要理解的是随后的代码、提示词或表格内容如何支持 AFlow 的 workflow 搜索。
1class ContextualGenerate(Operator):2 async def __call__(self, problem, context, mode: str = None):3 prompt = CONTEXTUAL_GENERATE_PROMPT.format(problem_description=problem, thought=context)4 fill_kwargs = {"context": prompt, "llm": self.llm}5 if mode:6 fill_kwargs["mode"] = mode7 node = await ActionNode.from_pydantic(GenerateOp).fill(**fill_kwargs)8 response = node.instruct_content.model_dump()9 return response10 11class CodeGenerate(Operator):12 async def __call__(self, problem, function_name, mode: str = None):13 prompt = GENERATE_CODEBLOCK_PROMPT.format(problem_description=problem)14 fill_kwargs = {"context": prompt, "llm": self.llm, "function_name": function_name}15 if mode:16 fill_kwargs["mode"] = mode17 node = await ActionNode.from_pydantic(CodeGenerateOp).fill(**fill_kwargs)18 response = node.instruct_content.model_dump()19 return response20 21 22class Format(Operator):23 async def __call__(self, problem, solution, mode: str = None):24 prompt = FORMAT_PROMPT.format(problem_description=problem, solution=solution)25 fill_kwargs = {"context": prompt, "llm": self.llm}26 if mode:27 fill_kwargs["mode"] = mode28 node = await ActionNode.from_pydantic(FormatOp).fill(**fill_kwargs)29 response = node.instruct_content.model_dump()30 return response31 32class Review(Operator):33 async def __call__(self, problem, solution, mode: str = None):34 prompt = REVIEW_PROMPT.format(problem_description=problem, solution=solution, criteria=self.criteria)35 fill_kwargs = {"context": prompt, "llm": self.llm}36 if mode:37 fill_kwargs["mode"] = mode38 node = await ActionNode.from_pydantic(ReviewOp).fill(**fill_kwargs)39 response = node.instruct_content.model_dump()40 return response41 42class Revise(Operator):43 async def __call__(self, problem, solution, feedback, mode: str = None):44 prompt = REVISE_PROMPT.format(problem_description=problem, solution=solution, feedback=feedback)45 fill_kwargs = {"context": prompt, "llm": self.llm}46 if mode:47 fill_kwargs["mode"] = mode48 node = await ActionNode.from_pydantic(ReviseOp).fill(**fill_kwargs)49 response = node.instruct_content.model_dump()50 return response51 52class Ensemble(Operator):53 async def __call__(self, solutions: List[str], problem: str, mode: str = None):54 answer_mapping = {}55 solution_text = ""56 for index, solution in enumerate(solutions):57 answer_mapping[chr(65 + index)] = index58 solution_text += f"{chr(65 + index)}: \n{str(solution)}\n\n\n"59 prompt = ENSEMBLE_PROMPT.format(solutions=solution_text, problem_description=problem)60 fill_kwargs = {"context": prompt, "llm": self.llm}61 if mode:62 fill_kwargs["mode"] = mode63 node = await ActionNode.from_pydantic(EnsembleOp).fill(**fill_kwargs)64 response = node.instruct_content.model_dump()65 66 answer = response.get("solution_letter", "")67 answer = answer.strip().upper()68 69 return {"solution": solutions[answer_mapping[answer]]}70 71class Test(Operator):72 def exec_code(self, solution, entry_point):73 fail_cases = []74 ...75 if fail_cases != []:76 return fail_cases77 else:78 return "no error"79 80 async def __call__(self, problem, solution, entry_point, test_loop: int = 3):81 for _ in range(test_loop):82 result = self.exec_code(solution, entry_point)83 if result == "no error":84 return {"result": True, "solution": solution}85 elif "exec_fail_case" in result:86 result = result["exec_fail_case"]87 prompt = REFLECTION_ON_PUBLIC_TEST_PROMPT.format(88 problem=problem,89 solution=solution,90 exec_pass=f"executed unsuccessfully, error: \n {result}",91 test_fail="executed unsucessfully",92 )93 node = await ActionNode.from_pydantic(ReflectionTestOp).fill(context=prompt, llm=self.llm, mode="code_fill")94 response = node.instruct_content.model_dump()95 solution = response["reflection_and_solution"]96 else:97 ... 98 result = self.exec_code(solution, entry_point)99 if result == "no error":100 return {"result": True, "solution": solution}101 else:102 return {"result": False, "solution": solution}103 104class Programmer(Operator):105 async def exec_code(code, timeout=180):106 def run_code():107 try:108 global_namespace = {}109 110 exec(code, global_namespace)111 except ...112 113 done_event = threading.Event()114 result = ["Error", "subprocess error"]115 116 def wrapper():117 nonlocal result118 result = run_code()119 done_event.set()120 121 with concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor:122 future = executor.submit(wrapper)123 try:124 if done_event.wait(timeout=timeout):125 return result126 else:127 future.cancel()128 return "Error", "Exceed time limit"129 finally:130 executor.shutdown(wait=False)131 132 async def code_generate(self, problem, analysis, feedback, mode):133 prompt = PYTHON_CODE_VERIFIER_PROMPT.format(problem=problem, analysis=analysis, feedback=feedback)134 fill_kwargs = {"context": prompt, "llm": self.llm, "function_name": "solve"}135 if mode:136 fill_kwargs["mode"] = mode137 node = await ActionNode.from_pydantic(CodeGenerateOp).fill(**fill_kwargs)138 response = node.instruct_content.model_dump()139 return response140 141 async def __call__(self, problem: str, analysis: str = "None"):142 code = None143 for i in range(3):144 code = await self.code_generate(problem, analysis, feedback, mode="code_fill")145 code = code["code"]146 status, output = await self.exec_code(code)147 if status == "Success":148 return {"code": code, "output": output}149 else:150 ...151 return {"code": code, "output": "error"}这段代码展示 AFlow 内置算子的实现方式,包括生成、代码生成、格式化、审阅、修订、集成、测试和程序执行等。算子把常见 agent 步骤封装成稳定接口,使搜索过程既能复用已有有效模式,又能通过代码组合形成新的 workflow。
Providing predefined operators can effectively enhance the search efficiency of AFlow. We implement six common operator structures, including: Generate (Contextual, Code), Format, Review & Revise, Ensemble, Test, and Programmer. For the Test Operator, we use the public test dataset of the dataset as test data. For datasets like MBPP that don't provide a public test dataset, we follow the setting in li2024debug where we use the first test case of each problem as public test data.
提供预定义算子可以有效提升 AFlow 的搜索效率。论文实现了六类常见算子,包括生成、格式化、审阅与修订、集成、测试和程序员算子。测试算子使用公开测试数据;如果数据集没有公开测试集,则采用每个问题的第一个测试用例作为公开测试数据。
Mapping workflow from Formulation to Code
Mapping workflow from Formulation to Code
从形式化定义映射到代码工作流
[title= An example of Workflow, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
这里是附录中的工作流示例代码框。随后的代码把形式化定义落到程序中:先生成多个候选解,再通过集成选择、测试执行和失败修复组成完整流程,用代码控制所有输入输出变量的传递。
1async def __call__(self, problem: str, entry_point: str):2 """3 Implementation of the workflow4 Custom operator to generate anything you want.5 But when you want to get standard code, you should use custom_code_generate operator.6 """7 solutions = []8 for _ in range(3): # Generate 3 solutions9 solution = await self.custom_code_generate(problem=problem, entry_point=entry_point, instruction=prompt_custom.CODE_GENERATE_PROMPT)10 solutions.append(solution['response'])11 12 best_solution = await self.sc_ensemble(solutions=solutions, problem=problem)13 14 test_result = await self.test(problem=problem, solution=best_solution['response'], entry_point=entry_point)15 16 if test_result['result']:17 return test_result['solution'], self.llm.cost_manager.total_cost18 else:19 # If the test fails, try to fix the solution20 fixed_solution = await self.custom(input=f"Problem: {problem}\nFailed solution: {best_solution['response']}\nError: {test_result['solution']}", instruction=prompt_custom.FIX_CODE_PROMPT)21 return fixed_solution['response'], self.llm.cost_manager.total_cost这段代码演示从形式化 workflow 到 Python 代码的映射:先生成多个候选解,再用集成算子选出最佳答案,随后运行测试算子;如果测试失败,就调用自定义修复提示词修正代码。它说明边由代码控制,而不是简单图上的两条出边。
In this example, • self.custom is the interface for building nodes, through which the Optimizer can generate/modify its prompts. • self.test and self.sc ensemble are interfaces for using Operators (In this example, this workflow only use 2 operators). • Edge in AFlow are represented through code, controlling the flow of all input/output variables between Nodes and Operators to form a complete workflow. Given this definition, the traditional concept of a 'node having two outgoing edges' does not apply to this formulation.
这个例子中,`self.custom` 是构建节点的接口,优化器可以通过它生成或修改提示词;`self.test` 和 `self.sc_ensemble` 是调用算子的接口;AFlow 中的边由代码表示,负责控制节点和算子之间所有输入输出变量的流动,因此传统图里“一个节点有两条出边”的说法并不直接适用于这里。
MCTS Algorithm of AFlow.
MCTS Algorithm of AFlow.
AFlow 的 MCTS 算法
1Require: Initial Workflow , Evaluator , Dataset , Number of rounds , Operators , Top k , Early stopping rounds 2Ensure: Optimal Workflow 3Initialize , , , , 4 RandomSplit(, 0.2, 0.8)5 Execute(, , )6 SelectHighVarianceInstances(, , )7for to :8 if :9 10 else:11 SelectParent()12 LoadContext(, )13 modification Optimizer(, )14 for to :15 Executor(, , )16 .append(, , )17 CalculateAverageScore([])18 CreateExperience(, , )19 .append()20 if :21 22 23 if The Top Workflows remains unchanged in rounds: # Early stopping24 return 25return 26procedure SelectParent():27 28 top_k_results ← sorted_results[:k]29 scores ← [result.scores for result in top_k_results]30 31 return SampleFromCategorical(probabilities)32procedure CalculateMixedProbabilities():33 length(), , , 34 for 35 for 36 for 37 38 return 39procedure Optimizer(, ):40 // LLM as Optimizer, generate new workflow and modification.41 return , 42procedure Executor(, , ):43 // LLM as Executor, execute workflow on dataset and return score and cost44 return , 该算法是附录中的 AFlow 详细版本。输入包括初始 workflow、评估器、数据集、迭代轮数、算子集合、top-k 个数和早停轮数;输出是最优 workflow。算法先初始化结果和经验记录,把数据划分为验证集与测试集,并用初始模板执行得到验证反馈。随后每一轮选择父 workflow,加载该路径上的经验,由优化器生成新 workflow 和修改说明,再重复执行五次以获得分数与成本。平均分、修改记录和成功/失败经验会被写回经验集合;若出现更高分则更新最优 workflow,若 top-k 长时间不变则提前停止。
案例研究
Case Study
案例研究
Case Study of AFlow
Case Study of AFlow
AFlow 案例研究
[title= Alpha Codium like workflow for MBPP, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
AFlow 案例。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1CODE_GENERATE_PROMPT = """2Generate a Python function to solve the given problem. Ensure the function name matches the one specified in the problem. Include necessary imports. Use clear variable names and add comments for clarity.3 4Problem:5{problem}6 7Function signature:8{entry_point}9 10Generate the complete function below:11"""12 13FIX_CODE_PROMPT = """14The provided solution failed to pass the tests. Please analyze the error and fix the code. Ensure the function name and signature remain unchanged. If necessary, add or modify imports, correct logical errors, and improve the implementation.15 16Problem:17{input}18 19Provide the corrected function below:20"""21 22GENERATE_TESTS_PROMPT = """23Given the problem and a potential solution, generate additional test cases to thoroughly evaluate the function. Include edge cases and typical scenarios. Format the test cases as assert statements that can be directly added to a Python test function.24 25Problem:26{input}27 28Generate 3-5 additional test cases as assert statements:29"""30 31async def __call__(self, problem: str, entry_point: str):32 solutions = []33 for _ in range(3): # Generate 3 solutions34 solution = await self.custom_code_generate(problem=problem, entry_point=entry_point, instruction=prompt_custom.CODE_GENERATE_PROMPT)35 solutions.append(solution['response'])36 best_solution = await self.sc_ensemble(solutions=solutions, problem=problem)37 # Generate additional test cases38 additional_tests = await self.custom(input=f"Problem: {problem}\nSolution: {best_solution['response']}", instruction=prompt_custom.GENERATE_TESTS_PROMPT)39 # Combine original problem and additional tests40 enhanced_problem = f"{problem}\n\nAdditional test cases:\n{additional_tests['response']}"41 test_result = await self.test(problem=enhanced_problem, solution=best_solution['response'], entry_point=entry_point)42 if test_result['result']:43 return test_result['solution'], self.llm.cost_manager.total_cost44 else:45 # If the test fails, try to fix the solution46 fixed_solution = await self.custom(input=f"Problem: {problem}\nFailed solution: {best_solution['response']}\nError: {test_result['solution']}", instruction=prompt_custom.FIX_CODE_PROMPT)47 return fixed_solution['response'], self.llm.cost_manager.total_cost这段 MBPP 案例 workflow 接近 AlphaCodium 式流程:生成多个代码解、集成选择、生成额外测试、执行测试,并在失败时修复代码。它展示 AFlow 能从空模板演化出类似人工专家设计的代码生成与验证流程。
AFlow demonstrates its ability to reduce human effort by evolving from an empty workflow to a solution highly similar to manually designed workflows like Tal2024Alpha in the code generation scenario. This showcases AFlow's capability to generate efficient workflows comparable to expert designs with minimal human intervention. [title= The optimal workflow generated for MATH, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
在代码生成场景中,AFlow 展示了减少人工设计的能力:它可以从空白流程逐步演化出与人工专家设计高度相似的方案。这个结果说明,搜索过程不只是微调提示词,而能自动组合生成、测试、修复和选择等步骤,形成接近专家流程的高效工作流。
1REFINE_ANSWER_PROMPT = """2Given the mathematical problem and the output from the code execution, please provide a well-formatted and detailed solution. Follow these guidelines:31. Begin with a clear statement of the problem.42. Explain the approach and any formulas or concepts used.53. Show step-by-step calculations, using LaTeX notation for mathematical expressions.64. Interpret the code output and incorporate it into your explanation.75. Provide a final answer, enclosed in \boxed{} LaTeX notation.86. Ensure all mathematical notation is in LaTeX format.9Your response should be comprehensive, mathematically rigorous, and easy to follow.10"""11GENERATE_SOLUTION_PROMPT = """12Please solve the given mathematical problem step by step. Follow these guidelines:131. State the problem clearly.142. Outline the approach and any relevant formulas or concepts.153. Provide detailed calculations, using LaTeX notation for mathematical expressions.164. Explain each step of your reasoning.175. Present the final answer enclosed in \boxed{} LaTeX notation.186. Ensure all mathematical notation is in LaTeX format.19Your solution should be thorough, mathematically sound, and easy to understand.20"""21DETAILED_SOLUTION_PROMPT = """22Provide a comprehensive, step-by-step solution to the given mathematical problem. Your response should include:231. A clear restatement of the problem.242. An explanation of the mathematical concepts and theorems involved.253. A detailed, logical progression of steps leading to the solution.264. Clear explanations for each step, including the reasoning behind it.275. All mathematical expressions and equations in LaTeX format.286. Visual aids or diagrams if applicable (described in text).297. A final answer clearly marked and enclosed in \boxed{} LaTeX notation.308. A brief explanation of the significance of the result, if relevant.31Ensure your solution is rigorous, easy to follow, and educational for someone learning the concept.32"""33async def __call__(self, problem: str):34 """35 Implementation of the graph36 """37 # Use Programmer to generate and execute Python code38 code_solution = await self.programmer(problem=problem)39 # Use Custom to refine and format the answer40 refined_solution = await self.custom(input=problem + f"\nCode output: {code_solution['output']}", instruction=prompt_custom.REFINE_ANSWER_PROMPT)41 # Generate a detailed step-by-step solution using Custom42 detailed_solution = await self.custom(input=problem, instruction=prompt_custom.DETAILED_SOLUTION_PROMPT)43 # Generate multiple solutions using Custom44 solutions = [45 refined_solution['response'],46 detailed_solution['response']47 ]48 for _ in range(2):49 solution = await self.custom(input=problem, instruction=prompt_custom.GENERATE_SOLUTION_PROMPT)50 solutions.append(solution['response'])51 # Use ScEnsemble to select the best solution52 final_solution = await self.sc_ensemble(solutions=solutions, problem=problem)53 return final_solution['response'], self.llm.cost_manager.total_cost这段 MATH 案例 workflow 先生成代码或推理结果,再根据执行输出整理最终数学答案。它体现 AFlow 会针对数学任务学习到“执行辅助 + 答案格式化”的结构。
This optimal workflow generated for the MATH task showcases the model's ability to generate complex, task-specific solutions from task-agnostic initial settings. It combines programmatic solutions with various reasoning strategies, culminating in an ensemble selection process, and spontaneously formats the answer into the required form. This adaptation demonstrates the model's flexibility in tailoring workflows to different problem domains, while maintaining sophisticated problem-solving structures.
MATH 任务的最优 workflow 展示了 AFlow 生成复杂、任务特定方案的能力。它从任务无关的初始设置出发,学会结合代码执行、推理和答案整理,让数学解答更可靠。
[title= The optimal workflow generated for MBPP, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
AFlow 案例。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1CODE_GENERATE_PROMPT = """2Generate a Python function to solve the given problem. Ensure the function name matches the one specified in the problem. Include necessary imports. Use clear variable names and add comments for clarity.3 4Problem:5{problem}6 7Function signature:8{entry_point}9 10Generate the complete function below:11"""12 13FIX_CODE_PROMPT = """14The provided solution failed to pass the tests. Please analyze the error and fix the code. Ensure the function name and signature remain unchanged. If necessary, add or modify imports, correct logical errors, and improve the implementation.15 16Problem:17{input}18 19Provide the corrected function below:20"""21 22async def __call__(self, problem: str, entry_point: str):23 """24 Implementation of the workflow25 Custom operator to generate anything you want.26 But when you want to get standard code, you should use custom_code_generate operator.27 """28 solutions = []29 for _ in range(3): # Generate 3 solutions30 solution = await self.custom_code_generate(problem=problem, entry_point=entry_point, instruction=prompt_custom.CODE_GENERATE_PROMPT)31 solutions.append(solution['response'])32 33 best_solution = await self.sc_ensemble(solutions=solutions, problem=problem)34 35 test_result = await self.test(problem=problem, solution=best_solution['response'], entry_point=entry_point)36 37 if test_result['result']:38 return test_result['solution'], self.llm.cost_manager.total_cost39 else:40 # If the test fails, try to fix the solution41 fixed_solution = await self.custom(input=f"Problem: {problem}\nFailed solution: {best_solution['response']}\nError: {test_result['solution']}", instruction=prompt_custom.FIX_CODE_PROMPT)42 return fixed_solution['response'], self.llm.cost_manager.total_cost这段 MBPP 案例 workflow 接近 AlphaCodium 式流程:生成多个代码解、集成选择、生成额外测试、执行测试,并在失败时修复代码。它展示 AFlow 能从空模板演化出类似人工专家设计的代码生成与验证流程。
The optimal workflow generated for the MBPP task simply combines operators with an ingenious FIX-CODE PROMPT, achieving the optimal workflow in the iteration at the fourteenth round. Although this workflow is simple, its score is extremely high and stable, demonstrating AFlow's potential to find the optimal cost-performance balance.
MBPP 最优 workflow 把算子和巧妙的修复代码提示词组合起来,在第 3 轮迭代就达到最佳效果。这个案例说明,对于代码任务,测试、集成和修复构成了非常有效的流程骨架。
[title= The optimal workflow generated for HotpotQA, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
AFlow 案例。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1FORMAT_ANSWER_PROMPT = """2Given the question and the best answer, format the final answer to be concise, accurate, and directly addressing the question. Ensure the answer is a clear, brief statement without additional explanation or reasoning. If the answer is a name, profession, or short phrase, provide only that information without forming a complete sentence.3 4For example:5- If the answer is a person's name, just provide the name.6- If the answer is a profession, state only the profession.7- If the answer is a short phrase, give only that phrase.8 9Do not include any prefixes like "The answer is" or "The profession is". Just provide the answer itself.10"""11 12async def __call__(self, problem: str):13 """14 Implementation of the workflow15 """16 solutions = []17 for _ in range(3):18 initial_response = await self.answer_generate(input=problem)19 thought_process = initial_response['thought']20 initial_answer = initial_response['answer']21 solutions.append(initial_answer)22 23 ensemble_result = await self.sc_ensemble(solutions=solutions)24 best_answer = ensemble_result['response']25 26 refined_solution = await self.custom(27 input=f"Question: {problem}\nBest answer: {best_answer}",28 instruction=prompt_custom.FORMAT_ANSWER_PROMPT29 )30 31 return refined_solution['response'], self.llm.cost_manager.total_cost这段 HotpotQA 案例 workflow 强调答案格式化和执行反馈。它把候选答案压缩为简洁准确的最终答案,说明检索问答任务中格式与最终表达会显著影响 F1。
The optimal workflow generated for the HotpotQA task demonstrates the effectiveness of execution feedback. Apart from logical reasoning, another factor affecting QA problem scores is effective formatting. AFlow can effectively identify the correct format and automatically perform formatting through learning from execution feedback, showcasing the efficacy of this design.
HotpotQA 最优 workflow 展示了执行反馈的重要性。除了逻辑推理,最终答案格式也会影响 F1;AFlow 通过反馈发现并强化了答案格式化这类看似细小但影响指标的环节。
[title= An ensemble structure that emerged in the GSM8K ablation experiment, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
AFlow 案例。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1SOLVE_APPROACH1_PROMPT = """2Solve the given math problem step by step using a standard algebraic approach. After solving, extract the final numerical answer and format it as follows:3 4Final Answer: [Insert the numerical value here]5 6Ensure that only the numerical value is provided after "Final Answer:", without any units or additional text.7 8Problem:9"""10 11SOLVE_APPROACH2_PROMPT = """12Solve the given math problem step by step using a visual or diagrammatic approach, if applicable. If not applicable, use an alternative method different from the standard algebraic approach. After solving, extract the final numerical answer and format it as follows:13 14Final Answer: [Insert the numerical value here]15 16Ensure that only the numerical value is provided after "Final Answer:", without any units or additional text.17 18Problem:19"""20 21SOLVE_APPROACH3_PROMPT = """22Solve the given math problem step by step using estimation or approximation techniques, then refine the answer for accuracy. After solving, extract the final numerical answer and format it as follows:23 24Final Answer: [Insert the numerical value here]25 26Ensure that only the numerical value is provided after "Final Answer:", without any units or additional text.27 28Problem:29"""30 31COMPARE_AND_SELECT_PROMPT = """32Compare the three solutions provided for the given math problem. Analyze each solution for correctness, completeness, and consistency with the problem statement. Select the most accurate and reliable solution, or if all solutions agree, confirm their consistency.33 34If the solutions differ, explain the differences and justify your selection of the most accurate answer. If all solutions agree, state this consistency.35 36Provide the final answer in the following format:37 38Final Answer: [Insert the numerical value here]39 40Ensure that only the numerical value is provided after "Final Answer:", without any units or additional text.41 42Problem:43"""44 45async def __call__(self, problem: str):46 """47 Implementation of the workflow48 """49 solution1 = await self.custom(input=problem, instruction=prompt_custom.SOLVE_APPROACH1_PROMPT)50 solution2 = await self.custom(input=problem, instruction=prompt_custom.SOLVE_APPROACH2_PROMPT)51 solution3 = await self.custom(input=problem, instruction=prompt_custom.SOLVE_APPROACH3_PROMPT)52 combined_solutions = f"Solution 1: {solution1['response']}\nSolution 2: {solution2['response']}\nSolution 3: {solution3['response']}"53 final_solution = await self.custom(input=problem + "\n" + combined_solutions, instruction=prompt_custom.COMPARE_AND_SELECT_PROMPT)54 return final_solution['response'], self.llm.cost_manager.total_cost这段 GSM8K 消融案例展示在没有预定义算子的条件下,AFlow 自发形成多路求解和选择结构。不同提示词生成不同解题路径,再通过选择或集成得到最终答案。
In the ablation study, where predefined operators were deliberately removed, AFlow surprisingly developed this simplified yet effective workflow. Most notably, it independently evolved an ensemble-like operator, mirroring a key aspect of the optimal workflow. This emergence of a multi-solution generation and selection process, despite reduced guidance, highlights AFlow's inherent tendency towards robust problem-solving strategies. The spontaneous development of this ensemble approach in a constrained environment underscores AFlow's ability to identify and implement effective techniques, even when operating with limited resources or instructions. This unexpected convergence between the ablated and optimal workflows further demonstrates AFlow's capacity for developing sophisticated, human-like problem-solving paradigms across different experimental conditions.
在移除预定义算子的消融实验中,AFlow 仍然发展出简化但有效的 workflow。尤其值得注意的是,它学到了多路解法和选择结构,说明 LLM 优化器可以在代码表示空间中独立设计有用流程。
Case Study of ADAS
Case Study of ADAS
ADAS 案例研究
[title= Iterative Knowledge-Enhanced Refinement workflow for HotpotQA, boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
ADAS 设计 workflow 时会把搜索历史中的所有 workflow 放进提示词,仅用生成顺序和分数区分它们。论文指出,这种线性历史容易造成信息混杂;代码案例显示 ADAS 会生成多角色和多步 refinement 结构,但未必能像 AFlow 一样沿树结构精确复用成功路径、避开失败路径。
1async def forward(self, taskInfo):2 import asyncio3 4 # Step 1: Initial reasoning by diverse expert agents5 initial_instruction = 'Please think step by step and solve the task based on your expertise.'6 expert_agents = [7 LLMAgentBase(['thinking', 'answer'], 'Expert Agent', role=role, temperature=0.7)8 for role in ['Reading Specialist', 'Logic Specialist', 'Generalist']9 ]10 11 async def run_expert(agent):12 return await agent([taskInfo], initial_instruction)13 14 initial_results = await asyncio.gather(*[run_expert(agent) for agent in expert_agents])15 16 combined_infos = [taskInfo] + [info for result in initial_results for info in result] # Flattening initial_results17 18 # Step 2: Iterative refinement with external knowledge integration19 max_iterations = 220 for iteration in range(max_iterations):21 # Retrieve external knowledge22 knowledge_retrieval_instruction = 'Retrieve relevant information from a knowledge base that can assist in refining the solution.'23 knowledge_retrieval_agent = LLMAgentBase(['retrieved_info'], 'Knowledge Retrieval Agent')24 retrieved_results = await knowledge_retrieval_agent(combined_infos, knowledge_retrieval_instruction)25 retrieved_info = retrieved_results[0]26 27 # Verify external knowledge28 verification_instruction = 'Verify the relevancy and accuracy of the retrieved information.'29 verification_agent = LLMAgentBase(['verified_info'], 'Verification Agent')30 verified_results = await verification_agent([taskInfo, retrieved_info], verification_instruction)31 verified_info = verified_results[0]32 33 # Refinement phase using verified knowledge34 refinement_instruction = 'Review and refine the insights provided by other agents using the verified external knowledge.'35 refinement_agents = [36 LLMAgentBase(['refined_thinking', 'refined_answer'], 'Refinement Agent', role=role, temperature=0.5)37 for role in ['Reading Specialist', 'Logic Specialist', 'Generalist']38 ]39 combined_infos_with_verification = combined_infos + [verified_info]40 41 async def run_refinement(agent):42 return await agent(combined_infos_with_verification, refinement_instruction)43 44 refinement_results = await asyncio.gather(*[run_refinement(agent) for agent in refinement_agents])45 combined_infos.extend([info for result in refinement_results for info in result]) # Flattening refinement_results46 47 # Step 3: Final synthesis agent integrates all refined insights48 final_decision_instruction = 'Synthesize all refined insights and provide a final answer.'49 final_decision_agent = LLMAgentBase(['thinking', 'answer'], 'Final Decision Agent', temperature=0.3)50 final_thinking, final_answer = await final_decision_agent(combined_infos, final_decision_instruction)51 52 return final_answer}这段 ADAS 案例代码展示另一种自动设计 workflow 的方式:把多角色初始推理、知识增强、反思、总结等步骤串联起来。论文用它对比说明,线性历史提示容易造成经验混杂,而 AFlow 的树结构更便于沿有效路径继续优化。
When designing workflows, ADAS incorporates all workflows from the search history into the prompt, distinguishing them only by their generation order and scores. However, the complex information embedded in the intricate structure of workflows, coupled with the accumulation of search iterations, the vast amount of information, and the continuously accumulating irrelevant information, poses significant challenges for LLM reasoning. ADAS stores experience from previous searches at the coarsest granularity—directly storing all complete workflows. This approach causes the LLM designing workflows in ADAS to behave more like an explorer of infinite possibilities within $$ rather than a designer seeking the optimal workflow.
ADAS 设计 workflow 时会把搜索历史中的所有 workflow 放进提示词,仅用生成顺序和分数区分它们。论文指出,这种线性历史容易造成信息混杂;代码案例显示 ADAS 会生成多角色和多步 refinement 结构,但未必能像 AFlow 一样沿树结构精确复用成功路径、避开失败路径。
As shown in the code in Appendix code:adashotpotqa, the optimal workflow discovered by ADAS assigns diverse roles and multiple steps for refinement and summarization. However, for multi-hop reasoning tasks, the correct approach is to continuously reduce the problem scale to single-hop reasoning. Contrary to this, ADAS's optimal workflow actually increases the problem scale, ultimately attempting to use the LLM's summarization ability to synthesize information, rather than gradually reducing the number of hops based on the characteristics of multi-hop reasoning scenarios.
ADAS 设计 workflow 时会把搜索历史中的所有 workflow 放进提示词,仅用生成顺序和分数区分它们。论文指出,这种线性历史容易造成信息混杂;代码案例显示 ADAS 会生成多角色和多步 refinement 结构,但未必能像 AFlow 一样沿树结构精确复用成功路径、避开失败路径。
Optimization Process of AFlow
Optimization Process of AFlow
AFlow 的优化过程
Taking AFlow's search process on the Math dataset as an example, we demonstrate how AFlow iteratively improves workflows based on tree-structured experience and execution feedback.
论文以 MATH 数据集上的搜索过程为例,展示 AFlow 如何基于树结构经验和执行反馈迭代改进 workflow。这个案例用于说明搜索过程不是黑箱随机尝试,而是能从分数变化、提示词修改和失败日志中逐步积累方向。
Tree-Structured Experience.
Tree-Structured Experience.
树结构经验
[title= Processed Experience (formatted as tree sturcture), boxrule=1pt, arc=0mm, colback=black!5!white, colframe=black!75!white, breakable, before skip=10pt, after skip=10pt, pad at break=2mm, parbox=false]
树结构经验。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1{2 "1": {3 "score": 0.4873949579831933,4 "success": {5 "2": {6 "modification": "Add the Programmer operator to generate and execute Python code for mathematical calculations, and use the Custom operator to refine and format the final answer.",7 "score": 0.52436974789915978 }9 },10 "failure": {11 "8": {12 "modification": "Add a ScEnsemble operator to generate multiple solutions and select the best one. This will help improve the accuracy of the final answer.",13 "score": 0.433613445378151214 }15 }16 },17 "2": {18 "score": 0.5243697478991597,19 "success": {20 "3": {21 "modification": "Add a ScEnsemble operator to improve the reliability of the final answer by generating multiple solutions and selecting the most consistent one.",22 "score": 0.527731092436974723 }24 },25 "failure": {26 "6": {27 "modification": "Add a ScEnsemble operator to improve the reliability of the final answer by generating multiple solutions and selecting the most consistent one.",28 "score": 0.472268907563025229 },30 "7": {31 "modification": "Add a ScEnsemble operator to improve the reliability of the final answer by generating multiple solutions and selecting the most consistent one.",32 "score": 0.524369747899159733 }34 }35 },36 "3": {37 "score": 0.5277310924369748,38 "success": {39 "14": {40 "modification": "Modify the Custom operator to generate a more detailed step-by-step solution, and add a new Custom operator to review and refine the final answer. This will improve the clarity, accuracy, and completeness of the solution process.",41 "score": 0.531092436974789942 },43 "5": {44 "modification": "Add a new Custom operator to generate a detailed step-by-step solution, and modify the ScEnsemble operator to compare and select the best solution from multiple approaches.",45 "score": 0.551260504201680746 },47 "9": {48 "modification": "Add a new Custom operator to generate a detailed step-by-step solution, and modify the ScEnsemble operator to compare and select the best solution from multiple approaches.",49 "score": 0.537815126050420150 }51 },52 "failure": {53 "10": {54 "modification": "Add a new Custom operator to generate a step-by-step solution, and modify the ScEnsemble operator to compare and select the best solution from multiple approaches.",55 "score": 0.504201680672268856 },57 "13": {58 "modification": "Modify the Custom operator to generate a more detailed step-by-step solution, and add a new Custom operator to refine and format the final answer. This will improve the clarity and accuracy of the solution process.",59 "score": 0.519327731092436960 },61 "4": {62 "modification": "Add a new Custom operator to generate multiple solutions using different approaches, then use ScEnsemble to select the best solution. This will increase the diversity of solutions and potentially improve accuracy.",63 "score": 0.064 }65 }66 },67 "9": {68 "score": 0.5378151260504203,69 "success": {},70 "failure": {71 "11": {72 "modification": "Add a new Custom operator to generate a detailed step-by-step solution with explanations, and incorporate it into the ensemble process. This will provide a more comprehensive approach to solving math problems.",73 "score": 0.515966386554621974 },75 "12": {76 "modification": "Add a new Custom operator to generate multiple solution approaches, then use ScEnsemble to select the best solution. This will increase the diversity of solutions and potentially improve accuracy.",77 "score": 0.078 },79 "16": {80 "modification": "Add a new Custom operator to generate multiple solution approaches, then use ScEnsemble to select the best solution. This will increase the diversity of solutions and potentially improve accuracy.",81 "score": 0.521008403361344682 }83 }84 },85 "14": {86 "score": 0.5310924369747899,87 "success": {},88 "failure": {89 "15": {90 "modification": "Add a new Custom operator to generate multiple solutions, then use ScEnsemble to select the best one. This modification aims to improve the accuracy and consistency of the final answer.",91 "score": 0.524369747899159692 },93 "18": {94 "modification": "Add a new Custom operator to generate a more detailed step-by-step solution, and modify the ScEnsemble operator to compare and select the best solution from multiple generated solutions.",95 "score": 0.517647058823529396 }97 }98 },99 "5": {100 "score": 0.5512605042016807,101 "success": {},102 "failure": {103 "17": {104 "modification": "Add a new Custom operator to generate multiple solutions using different approaches, and modify the ScEnsemble operator to select the best solution from a larger pool of candidates.",105 "score": 0.0106 },107 "19": {108 "modification": "Add a new Custom operator to generate a simplified solution, which will be used alongside the existing detailed solution to provide a more comprehensive answer. This simplified solution will be added to the list of solutions for the ScEnsemble operator to consider.",109 "score": 0.5445378151260505110 }111 }112 }113}这段 JSON 记录把搜索经验组织成树:每个节点保存分数、成功子节点、失败子节点和相对父节点的修改。它是 AFlow 区别于线性历史提示的关键证据,因为优化器可以知道某次改动发生在哪条路径上,以及它带来了提升还是退化。
More optimization trajectories will be made available in an open-source repository upon publication.
更多优化轨迹将在论文发布后通过开源仓库提供。
Less Effective Optimization Steps: • Round 1 $$ Round 8 (Score decreased from 0.4873 to 0.4336): The key change was the removal of the Programmer operator, relying solely on Custom + ScEnsemble, which lost the computational precision provided by programmatic solutions, demonstrating that removing concrete computational capabilities significantly hurts performance.
较低效的优化步骤之一是从第 1 轮到第 8 轮,分数从 0.4873 降到 0.4336。关键变化是移除了 Programmer 算子,转而依赖较简单的直接推理,因此失去了代码执行辅助带来的稳定性。
• Round 9 $$ Round 16 (Score decreased from 0.5378 to 0.5210): The key change involved simplifying the solution generation process without maintaining the review step, which resulted in the loss of the quality control aspect of solution refinement, showing that solution quality checks are important for maintaining performance.
另一个较低效步骤是第 9 轮到第 16 轮,分数从 0.5378 降到 0.5210。这次修改简化了解题生成过程,没有保持审阅和细化机制,导致答案质量下降。
Successful Optimization Steps: • Round 1 $$ Round 2 (Score improved from 0.4874 to 0.5244): The addition of the Programmer operator to generate executable Python code and the use of the Custom operator to refine results introduced concrete computational capabilities alongside human-like reasoning, creating a more robust solution approach and providing a foundation for both numerical accuracy and explanation quality.
成功步骤之一是第 1 轮到第 2 轮,分数从 0.4874 提升到 0.5244。新增 Programmer 算子后,workflow 可以生成并执行 Python 代码,从而让数学任务获得更可靠的中间反馈。
• Round 2 $$ Round 3 (Score improved from 0.5244 to 0.5277): The introduction of the ScEnsemble operator to select from multiple solutions added solution diversity and reliability through ensemble selection, creating a more robust system by considering multiple solution approaches.
第 2 轮到第 3 轮的提升来自 ScEnsemble 算子。它从多个解中选择答案,增加了解法多样性并降低单一路径出错的风险。
• Round 3 $$ Round 5 (Score improved from 0.52773 to 0.5513): The key change was the addition of detailed step-by-step solution generation, which enhanced solution clarity and comprehensiveness, ultimately improving the pedagogical value of solutions while maintaining accuracy.
第 3 轮到第 5 轮的提升来自更详细的逐步解题生成。这增强了方案的完整性,也让后续 refinement 更容易利用中间推理。
The tree-structured optimization process helped guide LLM workflow improvements in several ways: • Path Discovery: The tree structure allowed exploration of multiple optimization directions simultaneously, enabling the development of successful paths while pruning less successful branches, which facilitated the efficient discovery of effective combinations of operators.
树结构优化通过多种方式指导 LLM 改进 workflow:它允许探索多个优化路径,保留每条路径上的分数和修改,并使优化器能比较不同分支的效果,而不是只看一串混合历史。
• Incremental Improvement: Each node in the tree represents a specific workflow configuration, and the success/failure feedback at each step helped identify which modifications were beneficial, with the scoring system providing quantitative guidance for optimization decisions.
增量改进体现在每个树节点都代表一个具体 workflow 配置,节点上的成功或失败反馈帮助识别哪些修改有效、哪些修改会退化。
• Pattern Recognition: The tree structure made it easier to identify patterns in successful versus unsuccessful modifications, revealing common elements in high-scoring branches, such as the combination of Programmer + Custom + ScEnsemble, which informed future optimization decisions.
模式识别体现在树结构更容易区分成功修改和失败修改,揭示高分 workflow 中常见的元素,例如程序执行、集成、多步推理和答案格式化。
• Error Recovery: When a modification led to decreased performance, the tree structure facilitated easy backtracking, allowing exploration of alternative optimization paths from previous successful states and preventing the process from getting stuck in local optima.
错误恢复体现在当某个修改降低性能时,树结构允许搜索回到父节点或其他分支继续探索,而不是沿着失败方向不断累积错误。
Execution feedback.
Execution feedback.
执行反馈
In the process of optimizing the overall response generation, we implemented a concise and task-agnostic prompt: "Below are the logs of some results with the aforementioned Graph that performed well but encountered errors, which can be used as references for optimization: log ". This approach enabled execution feedback to assist LLM in workflow optimization. The following examples demonstrate how adjustments to the prompts enhanced the quality, consistency, and clarity of the answers, with particular emphasis on answer formatting as a key illustration.
在优化整体回答生成时,论文使用了一个简洁、任务无关的提示词来引入执行日志。提示词把 AFlow 执行后的结果日志、失败样例和期望输出交给优化器,使它能根据真实错误调整提示词或流程结构。
Optimization Steps: • Round 1 $$ Round 2: REFINE _ANSWER _PROMPT adds "Provide a final answer, enclosed in boxed LaTeX notation", resulting in the ability to identify patterns in the scoring feedback without knowing the specific rules of the scoring function.
从第一轮到第二轮,答案修订提示词新增了一个要求:最终答案需要用带框的数学格式给出。这个看似小的格式变化,让系统在没有直接知道标准答案的情况下,也能从评分反馈中识别出更稳定的输出模式,从而更容易抽取最终答案。
• Round 1 $$ Round 8: While REFINE _ANSWER _PROMPT adds "Provide a clear, concise final answer" to shift focus towards presenting answers more concisely, Round 8 lacks the strict LaTeX formatting constraints present in Round 2. This leads to Round 8 scoring lower than the baseline Round 1. However, the emphasis on concise answers also appears in the high-scoring Round 19, indicating that this remains a valid optimization direction.
从第 1 轮到第 8 轮,提示词虽然要求给出清晰简洁的最终答案,但第 8 轮过度关注形式,导致推理过程支持不足,表现下降。这个失败说明执行反馈不能只优化格式,还要保持解题信息传递。
• Round 3 $$ Round 13: REFINE _ANSWER _PROMPT introduces two new requirements: "If there are multiple possible answers, list all of them separated by commas within the boxed " and "Simplify expressions where possible without losing accuracy". While the former aims to standardize the format for multiple solutions, including this as a general instruction may interfere with the solution process. Statistical analysis shows that Round 13 contains 55 instances of comma-separated answers, notably higher than better-performing rounds such as Round 5 (43 instances) and Round 9 (42 instances).
从第 3 轮到第 13 轮,提示词增加了多个可能答案时用逗号列出、并提供详细解释的要求。这类修改改善了答案覆盖和格式稳定性,体现执行日志对提示词细节优化的作用。
Pareto Front: Detailed Cost-Performance Data
Pareto Front: Detailed Cost-Performance Data
帕累托前沿:详细成本-性能数据
Detailed cost-performance data for HumanEval. Executing AFlow(GPT-4o-mini) with deepseek achieves parity with GPT-4o IO at 4.55% of the cost. Executing AFlow(deepseek) with deepseek and AFlow(GPT-4o-mini) with GPT-4o-mini outperform GPT-4o IO at 5.92% and 8.05% of the cost, respectively.
这里给出代码生成基准上的详细成本性能数据。论文强调,用小型模型搜索出的流程再交给较便宜模型执行,可以用强模型直接调用极小一部分成本达到相近表现;另一种便宜模型搜索、小型模型执行的组合也能接近强模型直接调用,同时成本明显更低。
[h] 0.8pt 4pt 0.1cm -0.2cm @clcc@ Model & Method & Score (%) & Cost ( $) gpt-4o-mini & IO & 0.8702 & 0.0223 gpt-4o-mini & CoT & 0.8860 & 0.0277 gpt-4o-mini & CoT SC & 0.9160 & 0.1794 gpt-4o-mini & MedPrompt & 0.9160 & 0.2200 gpt-4o-mini & LLM Debate & 0.8930 & 0.2278 gpt-4o-mini & Self Refine & 0.8780 & 0.1232 gpt-4o-mini & AFlow(gpt-4o-mini) & 0.9470 & 0.0513 gpt-4o-mini & AFlow(deepseek) & 0.9084 & 0.0669 deepseek & IO & 0.8860 & 0.0127 deepseek & CoT & 0.8930 & 0.0180 deepseek & CoT SC & 0.8860 & 0.1168 deepseek & MedPrompt & 0.8860 & 0.1433 deepseek & LLM Debate & 0.8930 & 0.1484 deepseek & Self Refine & 0.9000 & 0.0802 deepseek & AFlow(gpt-4o-mini) & 0.9390 & 0.0291 deepseek & AFlow(deepseek) & 0.9466 & 0.0377 gpt-4o & IO & 0.9389 & 0.6371 gpt-4o & CoT & 0.9310 & 0.7772 gpt-4o & CoT SC & 0.9470 & 5.0345 gpt-4o & MedPrompt & 0.9390 & 6.1756 gpt-4o & LLM Debate & 0.9470 & 6.3952 gpt-4o & Self Refine & 0.9160 & 3.4589 gpt-4o & AFlow(gpt-4o-mini) & 0.9620 & 1.0111 gpt-4o & AFlow(deepseek) & 0.9542 & 1.6600 claude-3.5-sonnet & IO & 0.9084 & 0.6987 claude-3.5-sonnet & CoT & 0.9240 & 0.6412 claude-3.5-sonnet & CoT SC & 0.9390 & 4.1534 claude-3.5-sonnet & MedPrompt & 0.9160 & 5.0949 claude-3.5-sonnet & LLM Debate & 0.9080 & 5.2761 claude-3.5-sonnet & Self Refine & 0.8930 & 2.8536 claude-3.5-sonnet & AFlow(gpt-4o-mini) & 0.9540 & 1.1612 claude-3.5-sonnet & AFlow(deepseek) & 0.9466 & 1.3252
这张成本性能表给出 HumanEval 上各模型和方法的分数与花费。关键结论是:用 AFlow 搜索到的 workflow 可以让较便宜的执行模型达到接近甚至超过强模型直接调用的表现,例如 AFlow 配合 DeepSeek 的执行成本只有 GPT-4o IO 的一小部分。
Discussion on Workflow, Agentic Workflow, MultiAgent Systems
Discussion on Workflow, Agentic Workflow, MultiAgent Systems
关于 workflow、agentic workflow 与多智能体系统的讨论
In the field of LLM applications, concepts such as Workflow, Agentic Workflow, and MultiAgent Systems are frequently referenced, each with distinct emphases. The notion of Workflow in [cite: qiao2025benchmark] primarily focuses on the structured decomposition of real-world tasks, such as generating execution sequences for specific tasks in digital environments. [cite: qiao2025benchmark] work represents a significant advancement in workflow benchmarking through its comprehensive multi-faceted approach spanning function calls, problem-solving, embodied planning, and open-grounded planning scenarios.
在语言模型应用领域,工作流、智能体工作流和多智能体系统经常被同时提及,但三者侧重点不同。工作流更强调任务步骤和执行顺序,智能体工作流强调由语言模型节点、工具和反馈组成的流程,多智能体系统则常把不同节点解释为角色或代理之间的协作。AFlow 的代码表示可以把这些概念统一到可执行流程中。
Despite terminological differences, the multi-agent systems described in [cite: zhang2024agentprune, zhang2024gdesigner, zhuge2024gptswarm] are functionally equivalent to agentic workflows. Both consist of a series of LLM-invoking nodes that lack autonomous capability and execute in a predetermined logical sequence. Though the terminology varies, these approaches essentially describe identical technical architectures.
尽管术语不同,一些多智能体系统在功能上等价于 agentic workflow:多个角色或代理之间的信息传递可以被看作节点与边,协作协议可以被看作流程结构。因此 AFlow 的代码表示也能覆盖这类系统。
Meanwhile, [cite: niu2025flow] explores methods for dynamically adjusting workflows during task execution, enhancing the system's ability to address complex problems by modifying workflows in real-time based on execution feedback.
另有工作研究任务执行过程中动态调整 workflow,以提升系统处理复杂问题的能力。这与 AFlow 的目标相关,但 AFlow 更关注自动生成和优化可复用 workflow,而不是单次执行中的临时调整。
AFlow proposed in this paper focuses on the automated generation and optimization of workflows, aiming to reduce dependence on manually designed initial workflows while improving the scalability and generalizability of agentic workflows. This approach complements existing research and collectively advances the field of LLM applications.
本文提出的 AFlow 聚焦于自动生成和优化 workflow,目标是减少对人工初始 workflow 的依赖。通过代码表示、MCTS 和执行反馈,AFlow 能在不同任务上搜索出适合的流程结构。
Discussion On Open-ended Tasks
Discussion On Open-ended Tasks
关于开放式任务的讨论
Adapting AFlow for Open-ended Tasks
Adapting AFlow for Open-ended Tasks
将 AFlow 适配到开放式任务
While we emphasized AFlow's powerful capabilities in solving reasoning tasks with numerical feedback in the main body, there are many tasks in the real world without numerical feedback and non-reasoning requirements~[cite: dai2024mmrole]. These scenarios lack numerical feedback because for open-ended tasks, performance is typically evaluated by humans who propose the tasks, making it difficult to evaluate using fixed and quantitative criteria. By introducing LLM as a judge ~[cite: zheng2023judging], this challenge can be addressed to some extent, as the LLM-as-judge evaluation prompt can effectively incorporate human preferences to adaptively evaluate open-ended tasks. In this section, we discuss how to leverage LLM as a judge while maintaining AFlow's core architecture to search for agentic workflows for these types of tasks.
正文主要强调 AFlow 在有数值反馈的推理任务上的能力,但现实中还有许多任务缺少明确数值评估,例如创意写作、开放式研究想法和长文本生成。论文因此讨论如何把 AFlow 适配到开放式任务。
To extend AFlow's capabilities to open-ended tasks, we modified the original workflow optimize prompt by removing reasoning-specific instructions. The new prompt is as follows:
为了扩展到开放式任务,作者修改原始 workflow 优化提示词,移除只适合推理任务的指令。新的提示词仍要求构造图和提示词,但更强调内容质量、结构、创造力以及任务需求。
[title= Workflow optimize prompt for open-ended tasks, boxrule=2pt, arc=0mm, breakable]
开放式任务。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1PROMPT = """You are constructing a graph and corresponding prompts to jointly solve {type} problems. Referring to the provided graph and prompts, which form a basic example of a {type} solution approach, please reconstruct and optimize them. You may add, modify, or delete nodes, parameters, or prompts. Include your single modification enclosed in XML tags in your reply. Ensure they are complete and correct to avoid runtime failures.Use logical and control flow (such as IF-ELSE and loops) to achieve more advanced code representation.Ensure all prompts required by the current graph are included in `prompt_custom`. Do not include any additional prompts. The prompts you need to generate are limited to those used in `prompt_custom.XXX`. Other methods already have built-in prompts and are prohibited from being generated. Generate only the prompts needed by the graph and remove any unused prompts from `prompt_custom`.The generated prompts must not contain any placeholders. Considering information loss, complex graphs may yield better results, but insufficient information transmission might omit the solution. Ensure that the necessary context is included throughout the process.2"""这段代码是开放式任务版本的提示或评估器。它移除了只适合数值推理的约束,并用 LLM-as-a-Judge 从相关性、质量、结构和参考比较等维度打分,从而替代原先明确的数值评估函数。
For tasks without numerical feedback, we propose a evaluation prompt based on LLM as a Judge. We utilize GPT-4o as our evaluation model, implementing the following prompt for scoring open-ended tasks:
对于没有数值反馈的任务,论文提出基于 LLM-as-a-Judge 的评价提示词。它使用 GPT-4o 作为评估模型,从内容相关性、内容质量、连贯结构和参考比较四个维度打分,并要求给出简短理由和总分。
[title= Evaluation prompt, boxrule=2pt, arc=0mm, breakable]
开放式任务。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1EVAL_PROMPT = """You are an expert evaluator tasked with scoring responses to open-ended questions. You will be provided with:21. The original question/prompt32. A golden (reference) answer (if available)43. A candidate response to be evaluated5 6Please evaluate the candidate response on the following dimensions, each scored from 1-5. When no reference answer is provided, use your expert judgment to assess the expected quality level for the given task type:7 81. Content Relevance (1-5):9- 5: Perfectly addresses all aspects of the prompt10- 4: Addresses most key aspects with minor omissions11- 3: Addresses main points but misses some important elements12- 2: Only partially relevant to the prompt13- 1: Largely irrelevant or off-topic14 152. Content Quality (1-5):16- 5: Exceptional depth, insight, and originality17- 4: Strong analysis/creativity with good supporting details18- 3: Adequate development with some supporting elements19- 2: Superficial treatment with minimal development20- 1: Poor quality with major flaws in reasoning/execution21 223. Coherence and Structure (1-5):23- 5: Excellent organization with seamless flow24- 4: Clear structure with minor transition issues25- 3: Generally organized but some awkward transitions26- 2: Poorly organized with frequent disconnects27- 1: Chaotic or illogical structure28 294. Reference Comparison (1-5):30- 5: Matches or exceeds expected quality for this type of task31- 4: Slightly below ideal but strong performance32- 3: Moderately below ideal but acceptable33- 2: Significantly below expected quality34- 1: Far below acceptable quality standards35 36Please provide:371. Numeric scores for each dimension (1-5)382. Brief justification for each score (1-2 sentences)393. Total score (sum of the four dimensions, maximum 20 points)404. Summary feedback (2-3 sentences)41 42Format your response as:43Content Relevance: [score] points44- Justification: [brief explanation]45 46Content Quality: [score] points47- Justification: [brief explanation]48 49Coherence: [score] points50- Justification: [brief explanation]51 52Reference Comparison: [score] points53- Justification: [brief explanation]54 55Summary Feedback:56[2-3 sentences highlighting key strengths and areas for improvement]57 58<score>[sum of all dimensions](pure number)</score>59 60"""这段代码是开放式任务版本的提示或评估器。它移除了只适合数值推理的约束,并用 LLM-as-a-Judge 从相关性、质量、结构和参考比较等维度打分,从而替代原先明确的数值评估函数。
This evaluation framework replaces the original evaluation function in AFlow's executing evaluation stage, enabling assessment of open-ended tasks while maintaining consistent evaluation standards.
这个评估框架替代了 AFlow 执行评估阶段中的原始评估函数,使开放式任务也能获得相对一致的反馈信号。这样,AFlow 仍可以保持选择、扩展、评估和回传的搜索闭环。
案例研究
Case Study
案例研究
We demonstrate the effectiveness of our adapted AFlow through two open-ended task scenarios: long-form novel generation and academic idea generation. Both cases lack numerical feedback and utilize our adapted methodology. To evaluate AFlow's performance on these tasks, we first hired three human annotators at $10/hour to score and rank the results generated during AFlow's iteration process. Additionally, we compared results generated directly by LLM with those generated by AFlow to observe the differences. Due to space limitations, we provide the complete results of the two task generations in the supplementary materials.
这部分属于 案例研究。它围绕 AFlow 的 workflow 表示、搜索机制、实验设置或附录实现展开,强调把复杂 LLM 流程写成可执行结构,再通过评估反馈逐步优化。原文信息用于支撑后续讲解中关于节点、算子、代码边、MCTS 搜索和任务结果的分析。
Long-form Novel Generation
Long-form Novel Generation
长篇小说生成
In this case study, we employed Claude-3.5-sonnet as the execution and optimization model and GPT-4o as the evaluation model due to its strong language capabilities. The system was tested with a single question without reference answers:
长篇小说案例使用 Claude-3.5-sonnet 作为执行和优化模型,用 GPT-4o 作为评估模型,因为它具备较强语言能力。测试问题要求生成一篇约 20000 词的小说,主题是人的深层遗憾会改变其时间流速感知。
[title= Novel data, boxrule=2pt, arc=0mm, breakable]
长篇小说生成。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1{2"question":"Create a novel-length narrative, exactly 20,000 words long (please ensure this specific length is met), exploring a world where time's flow varies for each person based on their deepest regrets. The story should meticulously examine how emotional burdens affect temporal perception, with careful attention to maintaining the required length. Focus on developing several characters whose unique regrets create distinctly different experiences of time's passage.",3"requirement":"Write a long novel with emphasis on substantial length, logical interconnections between chapters, and refined language style.", 4"answer": "No reference answer"5}这段材料来自长篇小说生成案例。AFlow 把一次性生成改造成先写大纲、再写人物档案、再逐章生成的 workflow;与直接调用模型相比,这种分阶段结构更容易满足长文本、章节连贯和字数要求。
The optimized workflow obtained after eight iterations of AFlow was:
经过八轮迭代后,AFlow 得到的优化 workflow 先生成小说大纲,再生成角色档案,然后按章节逐步写作。这种分解使模型不必一次性完成整篇长文本,而是通过结构化计划维持连贯性。
[title= Novel generation workflow, boxrule=2pt, arc=0mm, breakable]
长篇小说生成。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1OUTLINE_PROMPT = """2Create a detailed outline for a novel based on the given requirements. Include:31. A list of main characters with their deepest regrets and how it affects their perception of time42. A chapter-by-chapter breakdown of the plot, ensuring logical interconnections53. Key themes and motifs to be explored throughout the novel64. A rough word count estimate for each chapter to aim for the required total length7 8Provide this outline in a structured format.9"""10 11CHARACTER_PROFILE_PROMPT = """12Based on the given requirements and outline, create detailed character profiles for each main character. For each character, include:131. Name, age, and physical description142. Background and personal history153. Their deepest regret and how it affects their perception of time164. Personality traits, motivations, and goals175. Relationships with other characters186. Character arc throughout the novel19 20Provide these profiles in a structured format.21"""22 23CHAPTER_PROMPT = """24Write a single chapter of the novel based on the given requirements, provided outline, and character profiles. Follow these guidelines:251. Adhere to the chapter structure from the outline262. Maintain logical interconnections with previous and future chapters273. Use refined language and vivid descriptions284. Develop characters' arcs based on their regrets and time perception295. Incorporate the key themes and motifs306. Aim for approximately 10,000 words per chapter31 32Write the complete chapter without stopping or summarizing. Do not include any meta-commentary or explanations outside the chapter text itself.33"""34 35 async def __call__(self, problem: str):36 """37 Implementation of the workflow38 """39 outline = await self.custom(input=problem, instruction=prompt_custom.OUTLINE_PROMPT)40 character_profiles = await self.custom(input=problem + f"\nOutline: {outline['response']}", instruction=prompt_custom.CHARACTER_PROFILE_PROMPT)41 42 novel = ""43 chapter_count = 10 # Adjust as needed44 for i in range(chapter_count):45 chapter = await self.custom(46 input=problem + f"\nOutline: {outline['response']}\nCharacter Profiles: {character_profiles['response']}\nChapter Number: {i+1}",47 instruction=prompt_custom.CHAPTER_PROMPT48 )49 novel += f"\n\nChapter {i+1}\n\n{chapter['response']}"50 51 return novel, self.llm.cost_manager.total_cost这段材料来自长篇小说生成案例。AFlow 把一次性生成改造成先写大纲、再写人物档案、再逐章生成的 workflow;与直接调用模型相比,这种分阶段结构更容易满足长文本、章节连贯和字数要求。
For comparison, below is the baseline response generated using only the Claude-3.5-sonnet, without any AFlow optimization:
作为对比,直接使用 Claude-3.5-sonnet 的基线回答拒绝生成完整 20000 词小说,只给出写作建议。这说明单次调用很难满足长文本长度和完整性的要求。
[title= LLM-Generated Novel, boxrule=2pt, arc=0mm, breakable]
长篇小说生成。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1I apologize, but I'm not able to generate a novel-length narrative of exactly 20,000 words in this format. Writing a full novel of that specific length would be an extremely lengthy and complex task that goes well beyond the scope of what I can produce in a single response. 2 3Additionally, maintaining an exact word count while crafting a cohesive narrative with developed characters and themes would be extremely challenging, even for human authors. Novels typically go through many drafts and revisions to reach their final form.4 5However, I can offer some suggestions for approaching this interesting concept:6 71. Start by outlining the key characters and their deepest regrets. Consider how each regret might impact their perception of time.8 92. Develop a basic plot structure that allows you to explore how these different temporal experiences intersect and affect each other.10 113. Consider the worldbuilding aspects - how does society function when everyone experiences time differently? What are the implications for relationships, work, etc?12 134. Begin writing scenes or chapters to explore these ideas, without worrying about exact word count initially. 14 155. As you write, keep track of word count and adjust pacing/detail as needed to work towards your target length.16 176. Plan for multiple drafts and revisions to refine the story and adjust length.18 19If you'd like, I could help brainstorm more specific ideas for characters or plot points within this concept. But for a full novel-length work, especially one with such precise length requirements, you'll likely need to undertake the writing process yourself over an extended period of time.这段材料来自长篇小说生成案例。AFlow 把一次性生成改造成先写大纲、再写人物档案、再逐章生成的 workflow;与直接调用模型相比,这种分阶段结构更容易满足长文本、章节连贯和字数要求。
Here is the simplified response generated using the AFlow-optimized workflow:
这里展示 AFlow 优化 workflow 生成的简化小说片段。输出包含多个章节、人物和时间主题,比直接调用模型更接近任务要求。
[title= AFlow-Generated Novel, boxrule=2pt, arc=0mm, breakable]
长篇小说生成。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1# Chapter 1: The Ticking of Regret2 3Emma Sinclair's fingers hovered over the keyboard, the cursor blinking accusingly on the blank document before her. The rhythmic ticking of the wall clock seemed to grow louder with each passing second, a constant reminder of the impending deadline looming over her. She glanced at the time display on her computer screen 2:37 PM. How was it possible that only three minutes had passed since she last checked?4...5 6# Chapter 2: The Scientific Discovery7 8Dr. Evelyn Harper stood at the podium, her silver hair gleaming under the harsh auditorium lights. Her piercing blue eyes scanned the crowd of scientists, doctors, and journalists who had gathered for her groundbreaking presentation. She took a deep breath, feeling the weight of decades of research pressing down on her shoulders.9...10...11 12# Chapter 10: A New Understanding of Time13 14The grand auditorium of the National Science Center buzzed with anticipation. Journalists, scientists, and curious members of the public filled every seat, their excited whispers creating a low hum that reverberated through the space. At the center of it all, Dr. Evelyn Harper stood behind the podium, her silver hair gleaming under the bright lights. She took a deep breath, her fingers lightly tracing the edges of her notes.15...16Dr. Harper cleared her throat, and the room fell silent. "Ladies and gentlemen, colleagues, and esteemed guests," she began, her voice clear and steady. "Today, I stand before you to present the culmination of years of research into what we once thought was immutable: the nature of time itself."17...18 19The sun shone brightly overhead, its warmth a reminder of the present moment. And in that moment, as they moved forward together, time flowed perfectly, neither too fast nor too slow. It simply was, and they were fully, completely present within it. The future beckoned, full of promise and possibility, and they stepped towards it with open hearts and minds, ready for whatever adventures time might bring.这段材料来自长篇小说生成案例。AFlow 把一次性生成改造成先写大纲、再写人物档案、再逐章生成的 workflow;与直接调用模型相比,这种分阶段结构更容易满足长文本、章节连贯和字数要求。
The optimized workflow (obtained after eight iterations) produced a 27,000-word novel, demonstrating significant improvements in both quality and efficiency compared to baseline responses. The cost and performance metrics across iterations show that AFlow can achieve high-quality long-form content generation with minimal resource expenditure.
八轮迭代得到的优化 workflow 生成了一篇约 27000 词的小说,相比基线在质量和效率上都有明显改进。迭代过程的成本与评分显示,AFlow 能以较少资源找到适合长文本生成的分阶段流程。
Novel generation Workflow Performance Comparison between LLM and Human Scores Across Different Rounds, with Rankings and Total Costs per Iteration
这张表比较长篇小说生成任务中不同迭代轮次的 LLM 评分、人类评分、排名和成本。第 8 轮达到最高 LLM 分数 20、人类平均分 19.3,并排名第一,说明开放式任务中改造后的 AFlow 也能通过评价器反馈改善 workflow。
Academic Idea Generation
Academic Idea Generation
学术想法生成
For this case study, we specifically chose GPT-4o-mini as the execution model and Claude-3.5-sonnet as the optimization model and GPT-4o as the evaluation model to better demonstrate AFlow's optimization capabilities. While the system was tested with 10 different questions, we present one representative example here:
学术想法生成案例使用 GPT-4o-mini 作为执行模型,Claude-3.5-sonnet 作为优化模型,GPT-4o 作为评估模型。论文用这个设置展示 AFlow 在较小执行模型上优化开放式研究构想的能力。
[title= Idea data, boxrule=2pt, arc=0mm, breakable]
学术想法生成。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1{2"question":"Given the current research landscape in Environmental Anthropology, propose a novel research idea through logical analysis",3"requirement": "Through rigorous analysis, propose a single research idea that addresses significant challenges, demonstrates feasibility with current technology. NOTE: Only ONE concrete idea should be provided - focus on developing a single, well-reasoned proposal rather than multiple options.",4"answer": "No reference answer"5}这段材料来自学术想法生成案例。workflow 先生成多个想法,再选择最有前景的方案,随后展开、评估并根据反馈修订,体现开放式任务中 AFlow 会学习到筛选与反思式流程。
The optimized workflow obtained after six iterations of AFlow was:
经过六轮迭代后,AFlow 得到的 workflow 包括生成多个想法、选择最有潜力的想法、展开研究方案、评估方案并修订最终提案。这比直接生成一个想法更能保证新颖性、可行性和结构完整性。
[title= Idea generation workflow, boxrule=2pt, arc=0mm, breakable]
学术想法生成。这一小节用于连接论文结构,帮助读者定位后续方法、实验或附录材料。
1GENERATE_IDEA = """2Given the current research landscape in the specified field, propose a novel and feasible research idea through logical analysis. Focus on developing a single, well-reasoned proposal that addresses significant challenges and demonstrates feasibility with current technology.3 4Your response should be concise, providing only the title and a brief description of the research idea in no more than 3 sentences.5"""6 7PRIORITIZE_IDEA = """8Analyze the given research ideas and prioritize the most promising one based on its potential impact and feasibility. Consider the following criteria:9 101. Novelty and originality112. Potential impact on the field123. Feasibility with current technology134. Alignment with current research trends14 15Provide a brief explanation (2-3 sentences) for your selection, highlighting its strengths in relation to the above criteria.16"""17 18ELABORATE_IDEA = """19Elaborate on the prioritized research idea. Provide a comprehensive analysis including:20 211. Research objective222. Methodology233. Expected outcomes244. Potential challenges25 26Ensure your response is well-structured, logically sound, and demonstrates the feasibility of the proposed research with current technology.27"""28 29EVALUATE_RESEARCH = """30Evaluate the elaborated research proposal. Consider the following aspects:31 321. Novelty and originality332. Feasibility with current technology343. Potential impact on the field354. Clarity and coherence of the proposal36 37Provide a concise evaluation highlighting strengths and areas for improvement.38"""39 40REFINE_PROPOSAL = """41Based on the elaborated idea and its evaluation, refine the research proposal. Address any weaknesses identified in the evaluation and enhance the proposal's strengths. Ensure that the refined proposal:42 431. Clearly states the research objective442. Outlines a feasible methodology453. Describes expected outcomes and their significance464. Addresses potential challenges and mitigation strategies47 48Present the refined proposal in a well-structured format suitable for academic submission.49"""50 51 async def __call__(self, problem: str):52 """53 Implementation of the workflow54 """55 ideas = []56 for _ in range(3): # Generate 3 ideas57 idea = await self.custom(input=problem, instruction=prompt_custom.GENERATE_IDEA)58 ideas.append(idea['response'])59 60 best_idea = await self.sc_ensemble(solutions=ideas, problem=problem)61 62 prioritized_idea = await self.custom(input=f"Ideas: {ideas}\nBest idea: {best_idea['response']}", instruction=prompt_custom.PRIORITIZE_IDEA)63 64 elaborated_idea = await self.custom(input=problem + f"\nPrioritized idea: {prioritized_idea['response']}", instruction=prompt_custom.ELABORATE_IDEA)65 66 evaluation = await self.custom(input=elaborated_idea['response'], instruction=prompt_custom.EVALUATE_RESEARCH)67 68 final_solution = await self.custom(input=elaborated_idea['response'] + f"\nEvaluation: {evaluation['response']}", instruction=prompt_custom.REFINE_PROPOSAL)69 70 return final_solution['response'], self.llm.cost_manager.total_cost这段材料来自学术想法生成案例。workflow 先生成多个想法,再选择最有前景的方案,随后展开、评估并根据反馈修订,体现开放式任务中 AFlow 会学习到筛选与反思式流程。
Due to space constraints, we provide the original LLM and AFlow-generated ideas in the supplementary materials. The results below demonstrate substantial improvements in idea generation quality and specificity compared to baseline responses, with consistent performance gains achieved after just six iterations.
受篇幅限制,论文把原始 LLM 和 AFlow 生成的完整想法放在补充材料中。这里的结果表明,AFlow 在六轮迭代后显著提高了想法生成的质量和具体性。
Idea generation Workflow Performance Comparison between LLM and Human Scores Across Different Rounds, with Rankings and Total Costs per Iteration
这张表比较学术想法生成任务的迭代结果。第 6 轮在人类评分和 LLM 评分上达到最好或接近最好,成本仍较低,说明 AFlow 在开放式任务里可以通过生成、筛选、细化、评估和修订等结构提升输出质量。
Discussion on Theoretical Properties of AFlow
Discussion on Theoretical Properties of AFlow
关于 AFlow 理论性质的讨论
Search Space Completeness
Search Space Completeness
搜索空间完备性
AFlow's search space completeness relies on two key properties: • Code-represented edge structure can express all valid node relationships • LLM expansion generates valid workflow modifications with non-zero probability These properties ensure AFlow can traverse from any initial workflow to any point in the search space, avoiding local optima.
AFlow 的搜索空间完备性依赖两个性质:代码表示的边结构能够表达所有有效节点关系,LLM 扩展以非零概率生成有效 workflow 修改。这两个性质使 AFlow 理论上可以从任意初始 workflow 移动到搜索空间中的任意位置,从而降低陷入局部最优的风险。
Convergence Properties
Convergence Properties
收敛性质
AFlow achieves optimal performance within finite iterations under three conditions: • Bounded evaluation function • Valid workflows maintained by code-represented edge structure • Non-zero probability of LLM generating improvements While the convergence sequence may not be strictly monotonic, MCTS properties and soft mixed probability selection balance exploration and exploitation to achieve convergence.
AFlow 在有限迭代内获得较优性能需要三个条件:评估函数有界、代码表示的边能保持 workflow 有效、LLM 以非零概率产生改进。虽然得分序列不一定单调上升,但 MCTS 性质和软混合概率选择共同平衡探索与利用。
Search Efficiency
Search Efficiency
搜索效率
AFlow enhances search efficiency through three key mechanisms. First, Operators increase the probability of generating improvements in each iteration by providing predefined node combinations that encode successful patterns. Second, Tree-Structured Experience enables efficient reuse of successful modifications while avoiding repeated failures through systematic path tracking. Finally, Execution Feedback provides direct performance measurements that guide the optimization process, helping AFlow identify and prioritize promising directions in the search space.
AFlow 通过三种机制提升搜索效率。第一,算子提供包含成功模式的预定义节点组合,提高每轮产生有效改进的概率。第二,树结构经验能复用成功修改并避免重复失败。第三,执行反馈提供直接性能测量,帮助搜索优先探索更有希望的方向。